In Bayesian statistics one uses a 'flat' prior distribution for
a parameter in the absence of knowledge or opinion about about
the parameter value. When the parameter is binomial success probability $p$ it may seem natural to use either a uniform prior $\mathsf{Beta}(\alpha=1,\beta=1)\equiv\mathsf{Unif}(0,1)$ or even the "bathtub shaped"
prior $\mathsf{Beta}(.5, .5).$
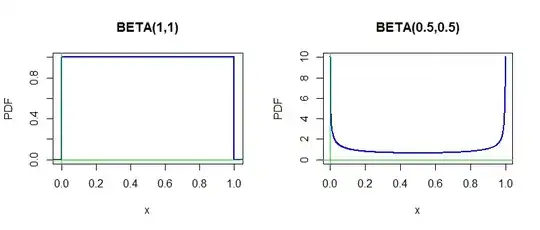
par(mfrow=c(1,2))
hdr1 = "BETA(1,1)"
curve(dbeta(x,1,1), -.05,1.05, ylab="PDF",
col="blue", lwd=2, xaxs="i", n=10001, main=hdr1)
abline(v=0, col="green2"); abline(h=0, col="green2")
hdr2 = "BETA(0.5,0.5)"
curve(dbeta(x,.5,.5), 0,1, ylab="PDF", col="blue", lwd=2,
ylim=c(0,10), n=1001, main=hdr2)
abline(v=0, col="green2"); abline(h=0, col="green2")
par(mfrow=c(1,1))
The purpose of using a flat prior distribution may be for the posterior
distribution on the parameter to be mainly due to the data.
For example, if the prior is $\mathsf{Beta}(1,1)$ and the data
show $x=23$ successes in $n=50$ trials, then the likelihood
is proportional to $p^x(1-p)^{n-x} = p^{23}(1-p)^{27}.$
Thus
the posterior distribution is $\mathsf{Beta}(24, 28)$ and
a 95% Bayesian credible interval for $p$ is $(0.33,\,0.600,$
which agrees numerically with a frequentist 95% frequentist Agresti-Coull
confidence interval $(0.33,\,0.60)$ to two decimal places.
qbeta(c(.025,.975),24,28)
[1] 0.3293001 0.5965812
p.est = 25/54
p.est + qnorm(c(.025,.975))*sqrt( p.est*(1-p.est)/54 )
[1] 0.3299707 0.5959553
Note: The distribution $\mathsf{Beta}(.5,.5)$ is called a Jeffreys prior. It can be argued that it is less informative as a prior than is $\mathsf{Beta}(1,1).$ The interval estimate $(0.33, 0.60)$ from this prior distribution is sometimes used as a frequentist CI:
qbeta(c(.025,.975),23.5,27.5)
[1] 0.3273505 0.5971336
