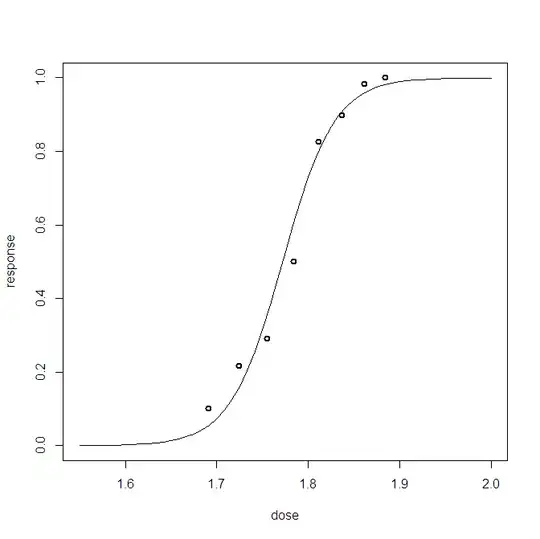
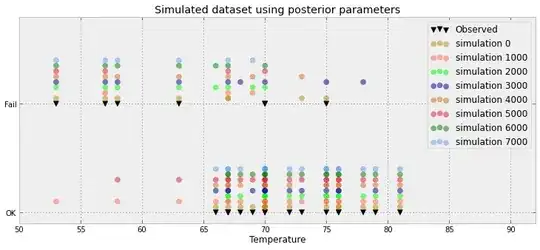
For a Bayesian logistic regression problem, I have created a posterior predictive distribution. I sample from the predictive distribution and receive thousands of samples of (0,1) for each observation I have. Visualizing the goodness-of-fit is less than interesting, for example:

This plot shows the 10 000 samples + the observed datum point (way in the left one can make out a red line: yea that's the observation). The problem is is that this plot is hardly informative, and I'll have 23 of them, one for each data point.
Is there a better way to visualize the 23 data points plus there posterior samples.
Another attempt:
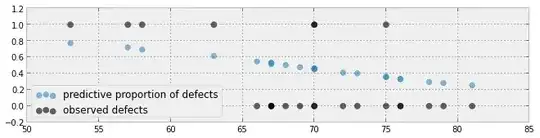
Another attempt based on the paper here