It is plain, from looking at the question geometrically, that the expected distance between two independent, uniform, random points within a convex set is going to be a little less than half its diameter. (It should be less because it's relatively rare for the two points to be located within extreme areas like corners and more often the case they will be near the center, where they are close.) Since the diameter of this rectangle is $50$, by this reasoning alone we would anticipate the answer to be a little less than $25$.
An exact answer is obtained from the definition of expectation as the probability-weighted value of the distance. In general, consider a rectangle of sides $1$ and $\lambda$; we will scale it up to the correct size afterwards (by setting $\lambda = 40/30$ and multiplying the expectation by $30$). For this rectangle, using coordinates $(x,y)$, the uniform probability density is $\frac{1}{\lambda}dx dy$. The mean distance within this rectangle then is given by
$$\int_0^\lambda\int_0^1\int_0^\lambda\int_0^1 \sqrt{(x_1-x_2)^2+(y_1-y_2)^2} \frac{1}{\lambda}dx_1 dy_1 \frac{1}{\lambda} dx_2 dy_2.$$
Using elementary integration methods this is straightforward but painful to do; I employed a computer algebra system (Mathematica) to obtain the answer
$$[2+2 \lambda ^5-2 \sqrt{1+\lambda ^2}+6 \lambda ^2 \sqrt{1+\lambda ^2}-2 \lambda ^4 \sqrt{1+\lambda ^2} +5 \lambda \text{ArcSinh}(\lambda)+5 \lambda ^4 \log\left(\frac{1+\sqrt{1+\lambda ^2}}{\lambda }\right)]/(30\lambda^2).$$
The presence of $\sqrt{1+\lambda^2}$ in many of these terms is no surprise: it is the diameter of the rectangle (the maximum possible distance between any two points within it). The appearance of logarithms (which includes the arcsinh) is also unsurprising if you have ever investigated average distances within simple plane figures: somehow it always shows up (a hint of this appears in integral of the secant function). Incidentally, the presence of $30$ in the denominator has nothing to do with the specifics of the problem involving a rectangle of sides $30$ and $40$: it's a universal constant.)
With $\lambda=4/3$ and scaling up by a factor of $30$, this evaluates to $\frac{1}{108} (871+960 \log(2)+405 \log(3)) \approx 18.345919\ldots$.
One way to understand the situation more deeply is to plot the mean distance relative to the diameter of $\sqrt{1+\lambda^2}$ for varying values of $\lambda$. For extreme values (near $0$ or much greater than $1$), the rectangle becomes essentially one-dimensional and a more elementary integration indicates the mean distance should reduce to one-third the diameter. Also, because the shapes of rectangles with $\lambda$ and $1/\lambda$ are the same, it is natural to plot the result on a logarithmic scale of $\lambda$, where it must be symmetric about $\lambda=1$ (the square). Here it is:
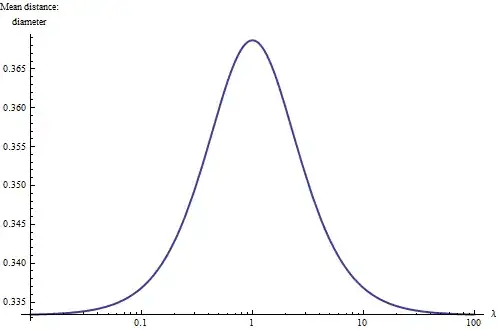
With this we learn a rule of thumb: the mean distance within a rectangle is between $1/3 \approx 0.33$ and (approximately) $0.37$ of its diameter, with the larger values associated with squarish rectangles and the smaller values associated with long skinny (linear) rectangles. The midpoint between these extremes is achieved roughly for rectangles with aspect ratios of $3:1$. With this rule in mind, you can just glance at a rectangle and estimate its mean distance to two significant figures.