I'm in the process of building an intuition for how hypothesis testing works and why we should use it. I'm not new to the topic — I've taken the usual introductory course in probability theory and statistics in uni. Still, I've always found it hard to make this concept "click". So here goes.
My current understanding is as follows.
- We set up a null-hypothesis and alternative hypothesis. For example:
$H_0: \mu = 0 \\ H_1: \mu > 0$ - We collect some data and compute the sample mean $\bar{x}$.
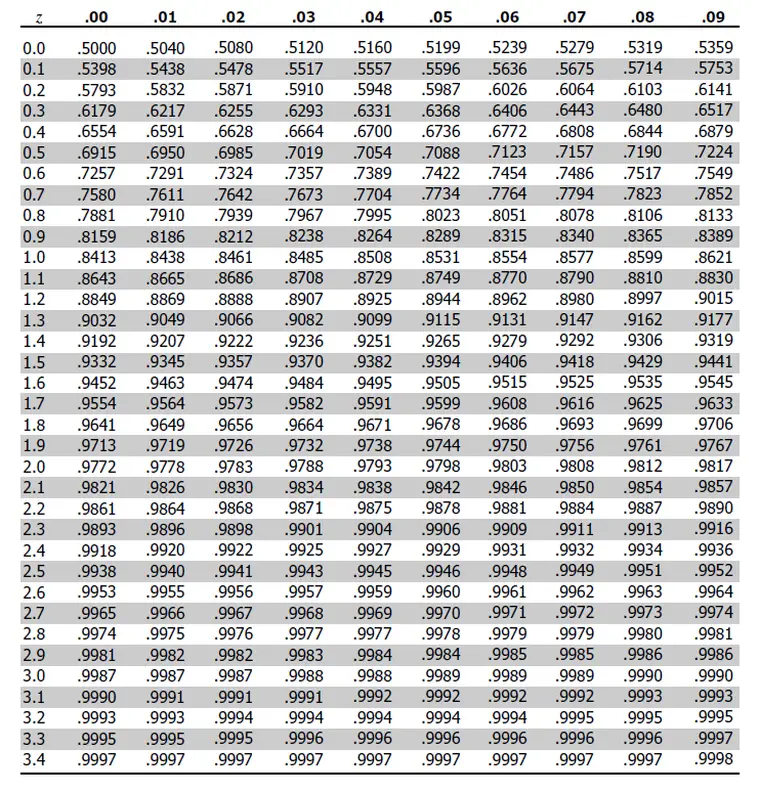
- Let's say we know the std. dev. $\sigma=1$ and we observe $\bar{x}=2$. Then we know that the chance of observing this mean or a more extreme mean — under the assumption of the null-hypothesis — is 0.02 (see z-table).
- We believe that this chance is so small (we believe that 0.05 is already sufficiently small), that we reject the null-hypothesis with the following rationale:
- Since the probability of finding even more extreme evidence against the null-hypothesis than our obtained evidence is very small, we conclude that our current evidence is already sufficiently strong to reject the null-hypothesis.
{kind=link}
This rationale makes sense, but what I find hard to understand is why we introduce this notion of "even more extreme evidence against the null-hypothesis". Why don't we just say: "The probability of finding $\bar{x}=2$ under the null-hypothesis is X. Since X is very small we reject the null-hypothesis". This would read much more intuitively I believe.
My suspicion is that the above question can be answered by the fact that the probability of a single value is undefined for a continuous random variable. So in order to make the math work, we introduce this notion of "or even more extreme evidence" and we can still draw valid conclusions. Can anybody tell me if that suspicion is correct?