I have some question which occupies myself for a while.
The entropy test is often used to identify encrypted data. The entropy reaches its maximum when the bytes of the analyzed data are distributed uniformely. The entropy test identifies encrypted data, because this data has a uniform distribution - like compressed data, which is classified as encrypted when using the entropy test.
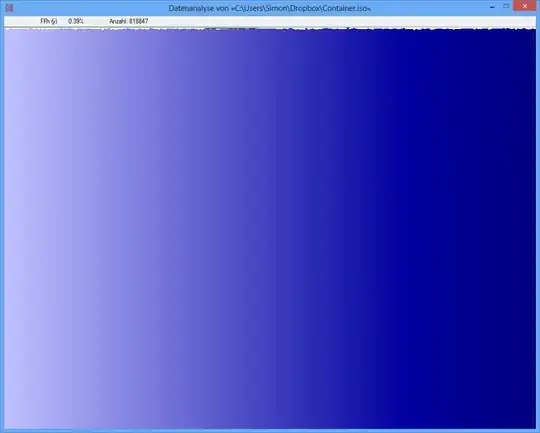
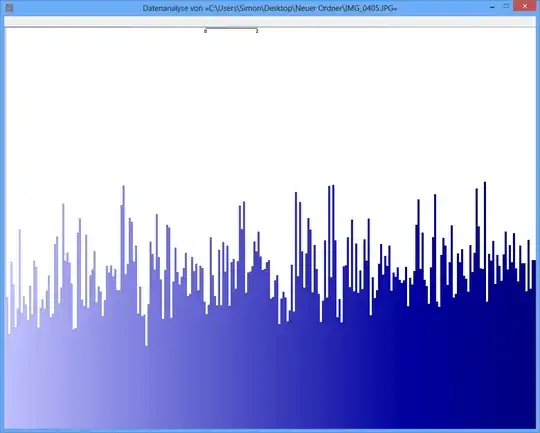
Example: The entropy of some JPG file is 7,9961532 Bits/Byte, the entropy of some TrueCrypt-container is 7,9998857. This means with the entropy test I cannot detect a difference between encrypted and compressed data. BUT: as u may see on the first picture, obviously the bytes of the JPG-file are not distributed uniformely (at least not as uniform as the bytes from the truecrypt-container).
Another test can be the frequency analysis. The distribution of each byte is measured and e.g. a chi-square test is performed to compare the distribution with a hypothetic distribution. as a result, I get a p-value. when i perform this test on JPG and TrueCrypt-data, the result is different.
The p-Value of the JPG file is 0, which means that the distribution from a statistical view is not uniform. The p-Value of the TrueCrypt-file is 0,95, which means that the distribution is almost perfectly uniform.
My question now: Can somebody tell me why the entropy test produces false positives like this? Is it the scale of the unit, in which the information content is expressed (bits per byte)? Is e.g. the p-value a much better "unit", because of a finer scale?
Thank you guys very much for any answer/ideas!
JPG-Image
 TrueCrypt-Container
TrueCrypt-Container