Model and Pseudocode
So I did some analysis in Python, though I used the pyMC library which hides all the MCMC mathy stuff. I'll show you how I modeled it in semi-pseudocode, and the results.
I set my observed data as $X=5, Y=10$.
X = 5
Y = 10
I assumed that $N$ has a Poisson prior, with the Poisson's rate a $EXP(1)$. This is a pretty fair prior. Though I could have chosen some uniform distribution on some interval:
rate = Exponential( mu = 1 )
N = Poisson( rate = rate)
You mention beta priors on $pX$ and $pY$, so I coded:
pX = Beta(1,1) #equivalent to a uniform
pY = Beta(1,1)
And I combine it all:
observed = Binomial(n = N, p = [pX, pY], value = [X, Y] )
Then I perform the MCMC over 50000 samples, burned-in about half of that. Below are the plots I generated after MCMC.
Interpretation:
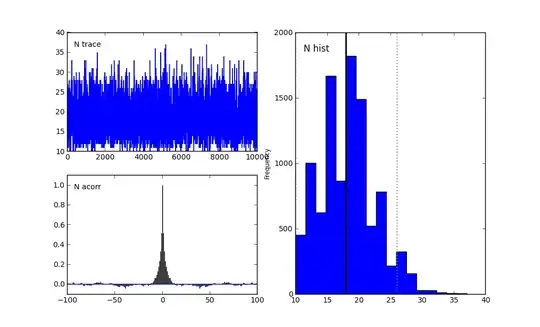
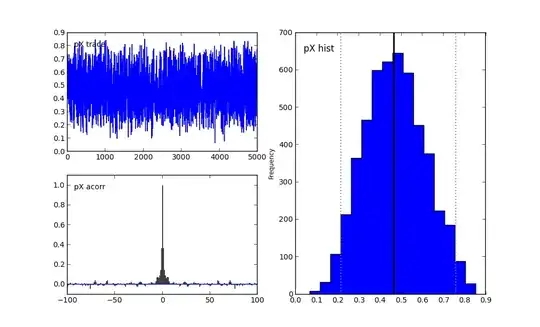
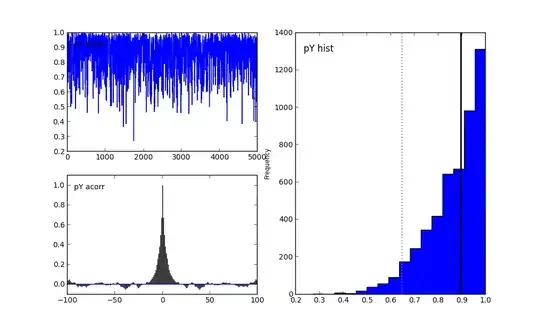
Let's examine the first graph for $N$. The N Trace graph are the samples, in order, I generated from the posterior distribution. The N acorr graph is the auto-correlation between samples. Perhaps there is still too much auto-correlation, and I should burn-in more. Finally, N-hist is the histogram of posterior samples. It looks like the mean is 13. Notice too that no samples were drawn from below 10. This is a good sign, as that would be impossible given the data observed was 5 and 10.
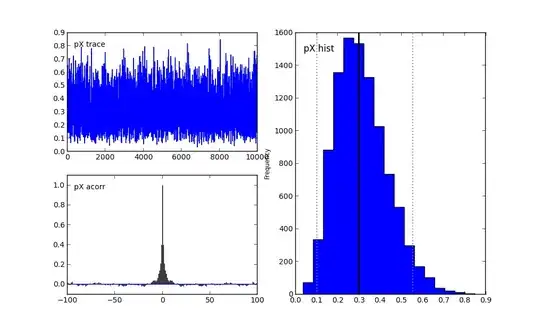
Similar observations can be made for the $pX$ and $pY$ graphs.
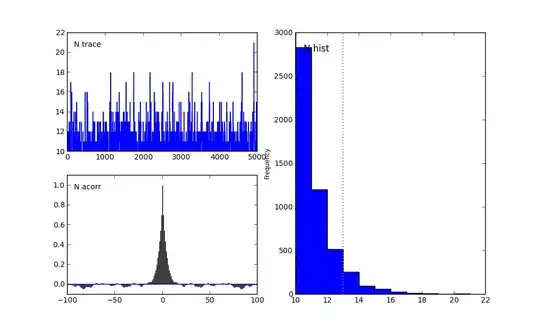
Different Prior on $N$
If we restrict $N$ to be a Poisson( 20 ) random variable (and remove the Exponential heirarchy), we get different results. This is an important consideration, and reveals that the prior can make a large difference. See the plots below. Note the time to convergence was much larger here too.
On the other hand, using a Poisson( 10 ) prior produced similar results to the Exp. rate prior.