I have 2 questions about GoogLeNet architecture, appreciate any help:
Even after reading this, I still don't understand where is the parameters reduction in the second convolutional layer:
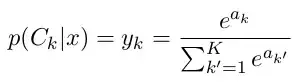
Specifically, if the number of input/output channels to/from the 1X1 conv layer was 64 as described in Table 1? aren't we end up with more parameters than if we had only the 3X3 layer?
I don't understand the number of parameters computation as shown in the column "params" in Table 1, for example it reads 2.7K params for the first layer but if we have 3 input channels (RGB) and 64 output channels with 7X7 filters, isn't it suppose to be 3 * 64 * 7 * 7 + 64 = 9472 paramaters?
