I have some data that looks like this:

Procrastinator has come up with one good suggestion for how to test hypotheses under this distribution, but it relies on some guesswork to fit constants. I would therefore feel more comfortable if I had multiple methods, and could check that they all agreed.
One thing I can do is find the mean of a bunch of samples, and by CLT this will approximate the normal distribution. In fact, this happens at reasonably small sample sizes. Here is my data with 1000 samples (with replacement) of 100 points each:
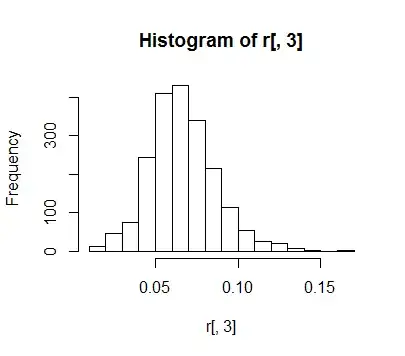
It looks fairly normal:
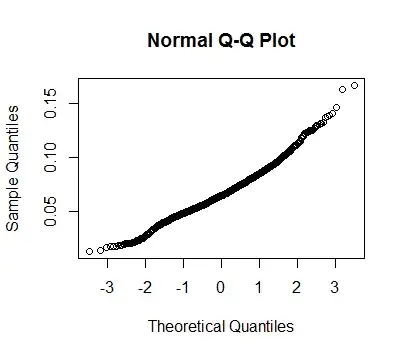
So would it be acceptable for me to compare two groups by first transforming them into a set of samples, and then using e.g. a T-test? Or am I introducing an unknown bias here?
(In this modified form, comparing their means does seem to be a useful metric, so I think a t test is good from that perspective.)