I wish to to some simple hypothesis testing of the form provided by T-Tests and ANOVA. However, my data is not normally distributed (it follows a Pareto distribution).
My understanding is that T-Tests make the assumption that the data is normally distributed and hence I won't be able to use them - is that correct? Is there something else I can do?
EDIT Here is some more info about my problem.
I'm trying to do some quality analysis on software defects, and am having trouble knowing where to start. One basic question I want to answer is:
Does software produced in department X have more defects than department Y?
As some background, we group changes to software as "patches", in which case the question becomes
Does the average patch from department X have more defects than department Y?
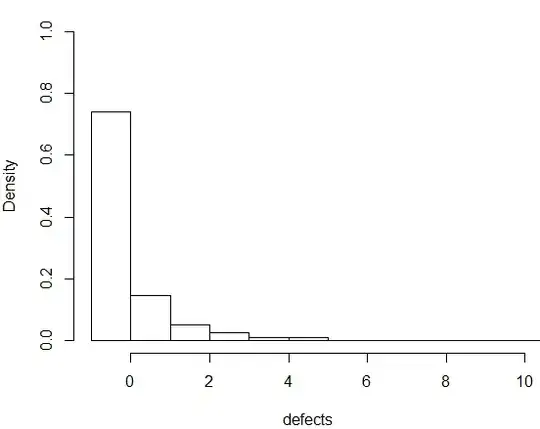
Here is a histogram of bugs / patch, N = 3700.
There is a philosophical issue of what it means to have "more" defects that I don't have a great answer to. The obvious choice for one of my limited knowledge is to compare the mean defects in each group, but as others have pointed out that's not clearly the best choice. The measure linked to by Procrastinator ($P(X<Y)$) seems like it captures my intuition well.