I will try to explain it visually
- First Label Dataset ( Label = Orange )
 WE can see the decision boundary learned by our model
WE can see the decision boundary learned by our model
Second Label Dataset ( Label = Blue)

Test Dataset ( Label = Blue,Orange, Model= Orange )
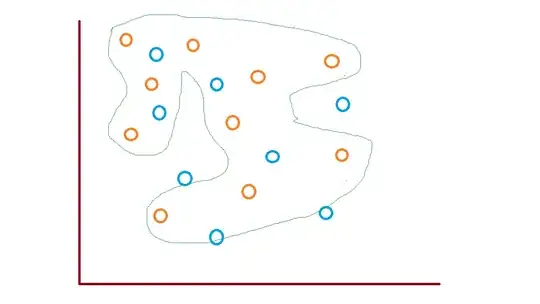
Inference
We can see that if we use the model learned by the First Label Dataset and test it on actual data ( in this case full data ), there are so many Blue data points that will be incorrectly labeled as Orange. So generally it is not a wise idea to create separate models
However, there are exceptions when we would like to evaluate the probability of a new point to lie in either of the two labels. In this case we allow models to learn the patterns of data representing a single label


