The basic recurrent neural network (RNN) cell is something that takes as input previous hidden state $h_{t-1}$ and current input $x_t$ and returns current hidden state
$$ h_t = \tanh(W_{hh}h_{t-1} + W_{xh}x_t) $$
Same applies to LSTM, but it is just a little bit more complicated as described in this great blog post. So answering your second question, at each step the RNN cell returns an output that can be used to make predictions. There are two ways of using RNN's, you can either process whole input sequence and look only at the last output state (e.g. process a whole sentence and then classify the sentiment of the sentence), or use the intermediate outcomes (in Keras this is the return_sequence=True parameter) and process them further, or make some kind of predictions (e.g. named-entity recognition per each word of a sentence). The only difference in here is that in the first case you simply ignore the intermediate states. If this is too abstract, the following figure (from the blog post referred above) may be helpful.
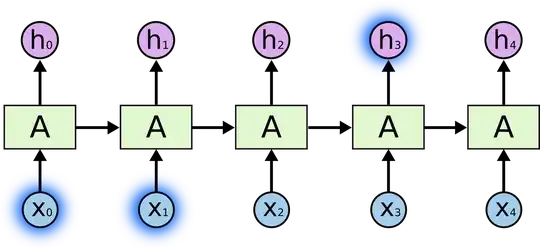
As you can see, at each step you have some output $h_t$ that is a function of current input $x_t$ and all the history, as passed through the previous hidden state $h_{t-1}$.
As about shape of the hidden state, this is a matrix algebra, so the shape will depend on the shape of the inputs and weights. If you use some pre-build software, like Keras, then this is controlled by the parameters of LSTM cell (number of hidden units). If you code it by hand, this will depend on the shape of the weights.
