Difference of two independent binomial distributed variables with the same parameters
I have a big bag of balls, each one marked with a number between 1 and n. The same number may appear on more than one ball. We can assume that the numbers on the balls follow a binomial distribution.
Now I pick a random ball from the bag, read its number x
and put the ball back. Then I pick a second random ball from the bag, read its number y and put it back.
The core of this question is answered by the difference of two independent binomial distributed variables with the same parameters $n$ and $p$. Let's phrase this as:
Let $X \sim Bin(n,p)$, $Y \sim Bin(n,p)$ be independent. Let the difference be $Z = Y-X$, then what is the frequency distribution of $\vert Z \vert$?
The more general situation has been handled on the math forum, as has been mentioned in the comments.
You can solve the difference in two ways.
Approximation with a normal distribution that has the same mean and variance. You have $\mu_X=\mu_y = np$ and $\sigma_X^2 = \sigma_Y^2 = np(1-p)$ and related $\mu_Z = 0$ and $\sigma_Z^2 = 2np(1-p)$ so you can approximate $Z \dot\sim N(0,2np(1-p))$ and for $\vert Z \vert$ you can integrate that normal distribution. $$P(\vert Z \vert = k) \begin{cases} \frac{1}{\sigma_Z}\phi(0) & \quad \text{if $k=0$} \\
\frac{2}{\sigma_Z}\phi(\frac{k}{\sigma_Z}) & \quad \text{if $k\geq1$} \end{cases}$$
which is close to a half normal distribution or chi distribution as you call it, except that the point $k=0$ does not have the factor 2.
Compute a sum or convolution taking all possible values $X$ and $Y$ that lead to $Z$. The probability for $X$ and $Y$ is:
$$f_X(x) = {{n}\choose{x}} p^{x}(1-p)^{n-x}$$
$$f_Y(y) = {{n}\choose{y}} p^{y}(1-p)^{n-y}$$
The probability for $Z=z \geq 0$ is
$$f_Z(z) = \sum_{k=0}^{n-z} f_X(k) f_Y(z+k)$$
and related
$$P(\vert Z \vert = k) \begin{cases} f_Z(k) & \quad \text{if $k=0$} \\
2 f_Z(k) & \quad \text{if $k\geq1$} \end{cases}$$
The sum can also be expressed with a generalized hypergeometric function. The function $f_Z(z)$ can be written as:
$$f_Z(z) = \sum_{k=0}^{n-z} \frac{(n!)^2 p^{2k+z} (1-p)^{2n-2k-z}}{(k)!(k+z)!(n-k)!(n-k-z)! } $$
or as a generalized hypergeometric series
$$f_Z(z) = \sum_{k=0}^{n-z} { \beta_k \left(\frac{p^2}{(1-p)^2}\right)^{k}} $$
with $$ \beta_0 = {{n}\choose{z}}{p^z(1-p)^{2n-z}}$$
and $$\frac{\beta_{k+1}}{\beta_k} = \frac{(-n+k)(-n+z+k)}{(k+1)(k+z+1)}$$
such that we can write $f_Z(z)$ in terms of a hypergeometric function
:
$$f_Z(z) = {{n}\choose{z}}{p^z(1-p)^{2n-z}} {}_2F_1\left(-n;-n+z;z+1;p^2/(1-p)^2\right)$$
if $p=0.5$ (ie $p^2/(1-p)^2=1$ ) then the function simplifies to
$$f_Z(z) = {{2n}\choose{z+n}}p^{2n}$$
and we could say if $p=0.5$ then $Z+n \sim Bin(2n,0.5)$.
This result for $p=0.5$ could also be derived more directly by $$f_Z(z) = 0.5^{2n} \sum_{k=0}^{n-z} {{n}\choose{k}}{{n}\choose{z+k}} = 0.5^{2n} \sum_{k=0}^{n-z} {{n}\choose{k}}{{n}\choose{n-z-k}} = 0.5^{2n} {{2n}\choose{n-z}}$$ using Vandermonde's identity
computational example:
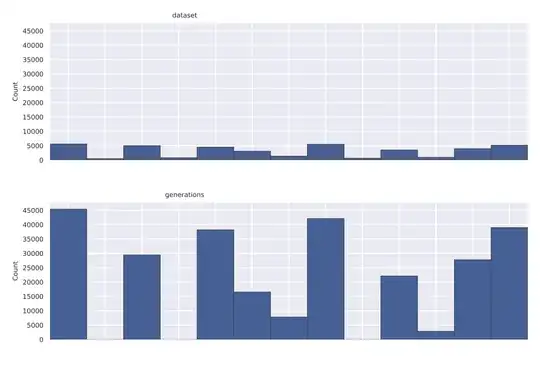
Below is an example of the above results compared with a simulation. The small difference shows that the normal approximation does very well.
library(hypergeo)
n <- 30
z <- 0:n
p <- 0.6
# simulate
set.seed(1)
ns <- 100000
X <- rbinom(ns,n,p)
Y <- rbinom(ns,n,p)
Z <- abs(X-Y)
# compute 1 exact
beta0 <- factorial(n)*p^z*(1-p)^(2*n-z)/factorial(n-z)/factorial(z)
ps1 <- beta0*Re(hypergeo(-n,-n+z,z+1,p^2/(1-p)^2))
# compute 2 normal approximation
ps2 <- dnorm(z,0,sqrt(2*n*p*(1-p)))
# plot
hist(Z,breaks = c(z,n+1)-0.5, freq=0, main = "Histogram of simulation compared with computed frequencies \n Bin(30,0.6)")
points(z,Re(ps1)*c(1,rep(2,n)),pch=21,col="black",bg="white",cex=1)
points(z,ps2*c(1,rep(2,n)),pch=3,col="black",bg="white",cex=1)
legend(15,0.20,c("computed exact probability","computed normal approximation"),
pch=c(21,3),cex=c(1,1))
Mixture distribution
I bought some balls, all blank. I take a binomial random number generator, configure it with some $n$ and $p$, and for each ball I paint the number that I get from the display of the generator. Then I put the balls in a bag and start the process that I described.
In the case that the numbers on the balls are considered random variables (that follow a binomial distribution). Then the frequency distribution for the difference $X-Y$ is a mixture distribution where the number of balls in the bag, $m$, plays a role.
You have two situations:
The first and second ball that you take from the bag are the same. This situation occurs with probability $\frac{1}{m}$. In this case the difference $\vert x-y \vert$ is equal to zero.
The first and second ball are not the same. This situation occurs with probability $1-\frac{1}{m}$. In this case the difference $\vert x-y \vert$ is distributed according to the difference of two independent and similar binomial distributed variables.
The above situation could also be considered a compound distribution where you have a parameterized distribution for the difference of two draws from a bag with balls numbered $x_1, ... ,x_m$ and these parameters $x_i$ are themselves distributed according to a binomial distribution.
computational example
Below is an example from a result when 5 balls $x_1,x_2,x_3,x_4,x_5$ are placed in a bag and the balls have random numbers on them $x_i \sim N(30,0.6)$. The probability for the difference of two balls taken out of that bag is computed by simulating 100 000 of those bags. (note this is not the probability distribution of the outcome for a particular bag which has only at most 11 different outcomes)
library(hypergeo)
n <- 30
z <- 0:n
p <- 0.6
nb <- 5
# simulate (make ns bags, and sample from them)
set.seed(1)
ns <- 100000
bags <- matrix(rbinom(ns*nb,n,p),ns)
X <- apply(bags,1, function(x) sample(x,1))
Y <- apply(bags,1, function(x) sample(x,1))
Z <- abs(X-Y)
# compute 1 exact
beta0 <- factorial(n)*p^z*(1-p)^(2*n-z)/factorial(n-z)/factorial(z)
ps1 <- beta0*Re(hypergeo(-n,-n+z,z+1,p^2/(1-p)^2))
# compute 2 normal approximation
ps2 <- dnorm(z,0,sqrt(2*n*p*(1-p)))
# plot
hist(Z,breaks = c(z,n+1)-0.5, freq=0, main = "Histogram of simulation compared with computed frequencies \n 5 balls in the bag with numbers sampled from Bin(30,0.6)")
points(z,(1-1/nb)*Re(ps1)*c(1,rep(2,n))+c(1/nb,rep(0,n)),pch=21,col="black",bg="white",cex=1)
points(z,(1-1/nb)*ps2*c(1,rep(2,n))+c(1/nb,rep(0,n)),pch=3,col="black",bg="white",cex=1)
legend(15,0.20,c("computed exact probability","computed normal approximation"),
pch=c(21,3),cex=c(1,1))

