After reading some of the helpful comments and answers, I've did some focused reading on my own.
As mentioned in other answers, this process is called Pruning and like many other ideas in the neural network area, it is not new. From what I can tell, it originates in LeCun's 1990 paper with the lovely "Optimal Brain Damage" (The paper cites some earlier works on network minimization from the late 80's but I didn't go that far down the rabbit hole). The main idea was to approximate the change in loss caused by removing a feature map and minimize it:
∆C(hi) = |C(D|W0) − C(D|W)|
Where C is the cost function, D is our dataset (of x samples and y labels) and W are the weights of the model (W0 are the original weights). hi is the output produced from parameter i, which can be either a full feature map in convolution layers or a single neuron in dense layers.
More recent works on the subject include:
"2016 - Pruning convolutional neural networks for resource efficient inference"
In this paper they propose the following iterative process for pruning CNNs in a greedy manner:
They present and test several criteria for the pruning process. The first and most natural one to use is the oracle pruning, which desires to minimize the difference in accuracy between the full and pruned models. However it is very costly to compute, requiring ||W0|| evaluations on the training dataset.
More heuristic criteria which are much more computationally efficient are:
- Minimum Weight - Assuming that a convolutional kernel with low L2 norm detects
less important features than those with a high norm.
- Activation - Assuming that an activation value of a feature map is smaller for less impotent features.
- Information Gain - IG(y|x) = H(x) + H(y) − H(x, y), where H is the entropy.
- Taylor Expansion - Based on the Taylor expansion, we directly approximate change in the loss function from removing a
particular parameter.
2016 - Dynamic Network Surgery for Efficient DNNs
Unlike the previous methods which accomplish this task in a greedy way, they incorporate connection splicing into the whole process to avoid incorrect pruning and make it as a continual network maintenance.
With this method, without any accuracy loss, they efficiently compress the number of parameters in LeNet-5 and AlexNet by a factor of 108× and 17.7× respectively.
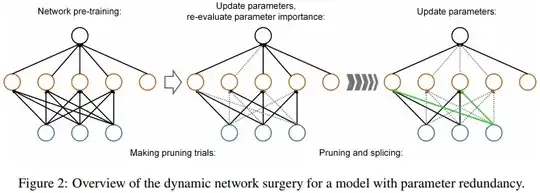
The figures and a much of what I written is based on the original papers.
Another useful explanation can be found in the following link: Pruning deep neural networks to make them fast and small.
A good tool for modifying trained Keras models is the Keras-surgeon. It currently enables easy methods to: delete neurons/channels from layers, delete layers, insert layers and replace layers.
I didn't find any methods for the actual pruning process (testing criteria, optimizing etc.)

