I have an engine that runs a game, and bots that perform strategies in it. I want to do different tests of versions of a single bot, to see how variations influence success. For instance, if I have Bot A1 and Bot A2, I might run the following trials:
Trial 0
- Bot A1
- Bot B
- Bot C
- Bot D
Trial 1
- Bot A2
- Bot B
- Bot C
- Bot D
Each trial consists of many games, so the end result is something like this:
Bot \ Place 1st 2nd 3rd 4th
A1 3 8 2 1
B 1 4 7 2
C 0 2 3 9
D 10 0 2 2
So, for the above trial, Bot A1 won the 3 games, was 2nd 8 times, came in last once, etc.
I'm looking for a way to compare two trials to see if the difference between them is statistically significant. What method is best for doing this?
(It's been a few years since I've done stats, so please forgive me if I'm missing information in this question. Also, if you think I'm completely off-base and there's another approach to determine which strategies are most effective, please let me know.)
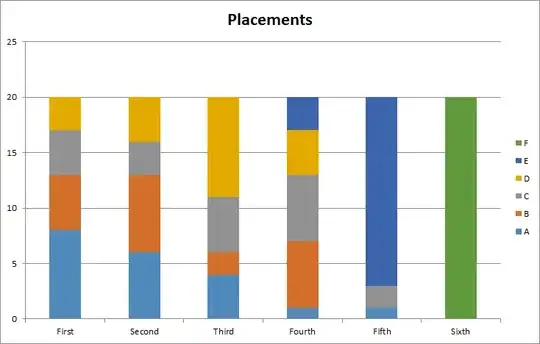
Update: I will arbitrarily decide that the way to rank bots is by looking at who comes in most in each place. (First, take whichever bot came in first the most times, then take whichever bot came in second the most times, etc.) For the above example, that would look like D, A1, B, C. Also, I'm using F#, for what it's worth.
Here is a chart generated from a single trial (actual run-through of the program; not related to the sample data above). The bots are named alphabetically by how well they did in the ranking I described in the previous paragraph (so A was better than B, etc).