In order to select features with the lasso, you can observe the drop out of coefficients at various shrinkages. At no shrinkage (0 penalty parameter), usually all M coefficients are non-zero, and at high enough shrinkage all coefficients are zero. In between these shrinkages, there will be points where individual coefficients drop out (leaving the top m features in the model). This is known as a regularization path.
You can visualize it in R using glmnet, using the iris dataset here:
library(glmnet)
data(iris)
X <- model.matrix(~ Sepal.Width + Petal.Length + Petal.Width, iris)
y <- iris$Sepal.Length
m_reg <- cv.glmnet(X, y, alpha = 1)
plot(m_reg$glmnet.fit, label = TRUE)
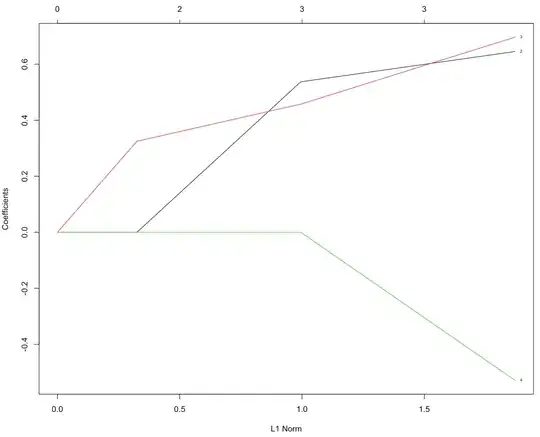
In predicting Sepal.Length, the first feature to drop out of the model (go to 0) due to shrinkage is Petal.Width (label 4); the last feature to drop out is Petal.Length (label 3). If you wanted the most parsimonious model with m = 2 features, the lasso gives Sepal.Length ~ Sepal.Width + Petal.Length
