I defined the distance between each observation and its centroid by:
dist=sum((X[,i]-Y[,j])^2)
# X is a 2*n observations matrix, Y is a 2*k centroids matrix
# n is the number of observations
Then I created a variable energy which represents the sum of dist for all observations.
I did that for k varying from 1 to 20 and I got these graphs: (It is energy vs. k)
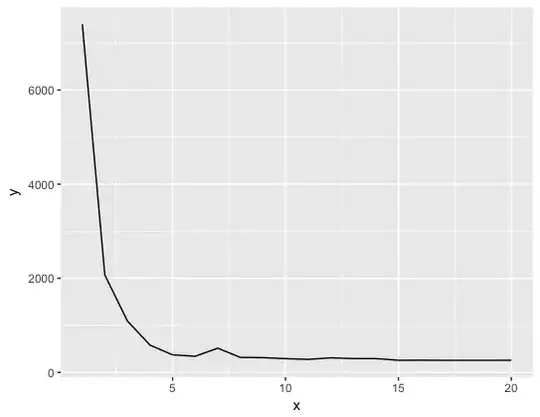
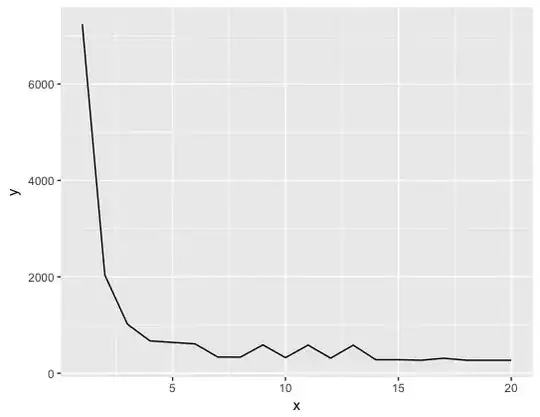
Why increasing k can increase the sum of squared residuals?