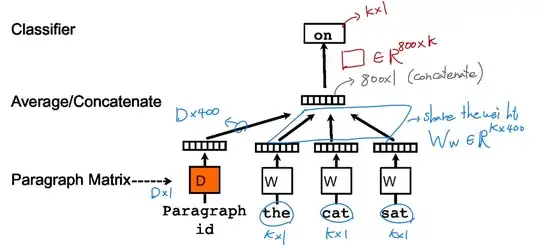
Below, I have a simple diagram explaining the matrix dimension of word2vec. My goal is to expand this graph to incorporate document vectors for doc2vec. However, I'm having trouble understanding the original paper, specifically about how to incorporate the weight parameters of documents. Let D be the number of documents to train and M be the hidden layer size for the documents. How would the doc2vec architecture look like in terms of matrix dimensions?