I'd like to generate a random square matrix such that the rows are normalized to one and the diagonal elements are the maximum of their column. If there an efficient way to sample these matrices uniformly?
$2 \times 2$ matrices are straightforward to create. The first column is generated by sampling two independent uniforms from $[0,1]$ and moving the maximum to the first entry. The second column is then the complement of the first. My attempts to follow an analogous procedure in higher dimensions feel very ad-hoc, and most troublesomely, give a very different distribution for the final complemented column than the others. Is some type of rejection sampling going to be my best bet?
The motivation is to generate likelihood matrices, with the rows being states of the world and columns being observed signals. Each signal is most likely to occur in its corresponding state, but isn't necessarily the most likely signal in that state.
Edit: The exact distribution doesn't matter, other than it seem natural. I would like to avoid the diagonal also being maximal for the rows though.
Here is my own previous ah-hoc attempt.
gen.likelihood.matrix <- function(T){
# T: Number of states
mat <- matrix(runif(T^2), nrow=T) # Intialize with uniform variates
diag(mat) <- 1 # To guarantee diag is max in column
candidate.mat <- matrix(nrow=T, ncol=T)
# Loop to check for constraint satisfaction
for(k in 1:100){
weights <- runif(T-1)
weights <- weights / sum(weights)
for(i in 1:T){
# Rescale columns
candidate.mat[i,-T] <- mat[i,-T] * weights
# Replace last column with complement to meet row constraint
candidate.mat[i,T] <- 1 - sum(candidate.mat[i,-T])
}
# Does the last column meet the maximality constraint?
if(candidate.mat[T,T] > max(candidate.mat[-T,T])){
# Shuffle to minimize the distortion from last column
reorder <- sample(1:T,T)
return(candidate.mat[reorder,reorder])
}
}
# Recurse to get new initial values if necessary
return(genLikeliMatrix(T))
}
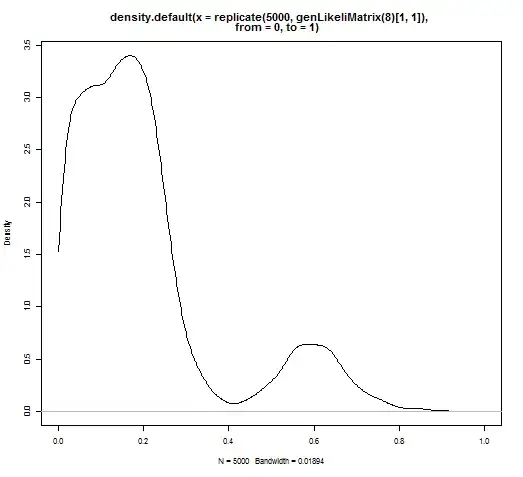
This works in terms of giving me matrices efficiently, but I get a weird bimodal distribution on the diagonal due to how I handle the last column.