A random population sample was surveyed. They were asked if they eat vegetarian diet. If they answered yes, they were also asked to specify how long they’ve been eating vegetarian diet without interruption. I want to use this data to calculate average length of adherence to vegetarianism. In other words, when someone becomes vegetarian, I want to know long on average they stay vegetarian. Let’s assume that:
- All respondents gave correct and accurate responses
- World is stable: popularity of vegetarianism is not changing, average length of adherence is not changing either.
My reasoning so far
I found it helpful to analyse a toy model of the world, where at the beginning of every year two people become vegetarians. Every time, one of them stays vegetarian for 1 year and another for 3 years. Obviously, the average length of adherence in this world is (1 + 3) / 2 = 2 years. Here is a graph that illustrates the example. Each rectangle represents a period of vegetarianism:

Let’s say we take a survey in the middle of year 4 (red line). We get the following data:
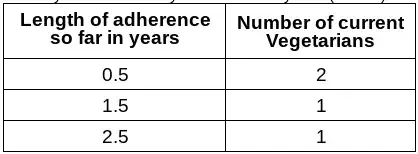
We’d get the same data if we took the survey at any year, starting year 3. If we just average the responses we get:
(2* 0.5 + 1.5 + 2.5)/4 = 1.25
We underestimate because we assume that everyone stopped being vegetarians right after survey, which is obviously incorrect. To obtain an estimate that is closer to the real average times that these participants would remain vegetarian, we can assume that on average, they reported a time about halfway through their period of vegetarianism and multiply reported durations by 2. In a large survey drawing randomly from the population (like the one I’m analysing), I think this is a realistic assumption. At least it’d give a correct expected value. However, if doubling is the only thing we do, we get average of 2.5, which is an overestimate. This is because the longer person stays vegetarian, the more likely (s)he is to be in the sample of current vegetarians.
I then thought that the probability that someone is in the the sample of current vegetarians is proportional to their length of vegetarianism. To account for this bias, I tried to divide number of current vegetarians by their predicted length of adherence:
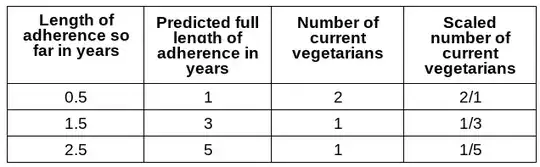
However, this gives an incorrect average as well:
(2*1 + ⅓ * 3 + ⅕ * 5)/(2 + ⅓ + ⅕) = 4 / 2.533333 = 1.579 years
It’d give the correct estimate if number of vegetarians were divided by their correct lengths of adherence:
(1 + ⅓ * (1 + 3 + 5))/(1 + ⅓ * 3) = 2 years
But it doesn't work if I use predicted lengths of adherence and they are all I have in reality. I don’t know what else to try. I read a bit about survival analysis but I’m not sure how to apply it in this case. Ideally, I would also like to be able to calculate a 90% confidence interval. Any tips would be greatly appreciated.
EDIT: It may be possible that the question above has no answer. But there was also another study that asked a random sample of people if they are/were vegetarian and how many times they've been vegetarian in the past. I also know age of everyone in both studies and some other things. Maybe this information can be used in conjunction to the survey of current vegetarians to get the mean somehow. In reality, the study I talked about is just one piece of the puzzle, but a very important one and I want to get more out of it.