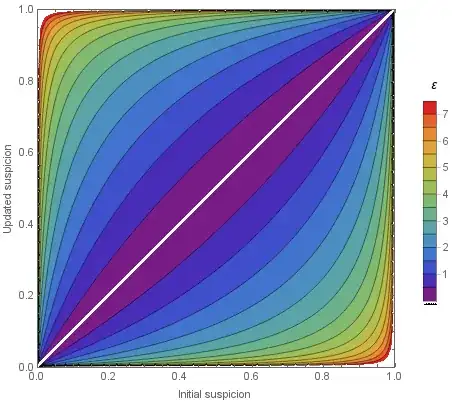
Some insight can be gained with basic algebraic manipulation of the inequality. Re-arranging gives:
$$\ln \mathbb{P}(K(D_1) \in \mathcal{S}) - \ln \mathbb{P}(K(D_2) \in \mathcal{S}) \leqslant \varepsilon.$$
Under $\varepsilon$-differential privacy, this inequality holds over all data sets $D_1$ and $D_2$ that differ by only one element, and all sets $\mathcal{S}$. Thus, we can see that $\varepsilon$ represents an upper bound on the logarithmic difference between the probabilities of the events $K(D_1) \in \mathcal{S}$ and $K(D_1) \in \mathcal{S}$. That is, under $\varepsilon$-differential privacy the value $\varepsilon$ gives an upper bound on the logarithmic difference between the probabilities that the algorithm output of two similar data sets (differing by one element) fall within any set. So the relevant ranges you are specifying for this value are giving ranges of values for upper bounds on this logarithmic difference.