The constant represents the y-intercept when all the variables that are in the model are zero. If you add a variable with a non-zero mean it may have a dramatic effect on the intercept. Specifically, if the IVs are themselves related, the coefficients of the smaller model (including the intercept) should be expected to be different.
For some discussion of this sort of effect, see the section in Intuition in the wikipedia article on omitted variable bias. The impact of the intercept is mentioned there.
[There are several posts on site discussing the effect on coefficients of variables included in both models -- e.g. see this one, but as with that question, they typically tend not to focus on the intercept]
(This effect doesn't imply that the coefficients of the larger model are themselves unbiased; there may be further important variables that are in turn related to variables already in the model)
However, the intercept may change even when the IVs are unrelated to each other, as long as the means of the additional variables are not 0. If the means of the omitted variables are large and they're related to the DV, the effect can be substantial.
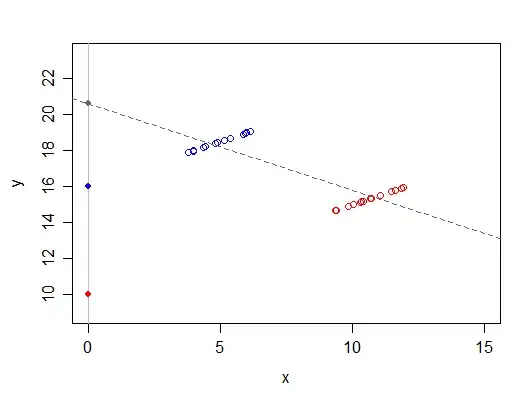
Consider the following simple example, which has no error in it for simplicity of illustration (the data are represented by open circles, the filled circles mark potential intercept-values depending on the model):
The response, $y$ is a linear function of two variables, $x$ and a grouping variable $z$. If you code the lower (red) group as $0$ then the fitted intercept will be $10$. If you code the upper (blue) group as $0$ then the fitted intercept will be $16$. If you omit the variable $z$ (in effect, both groups are now coded as $0$), the intercept will be at the grey dot (close to $12$ in this case). If $x$ and $z$ were perfectly uncorrelated the coefficient of $x$ would be correct (though its standard error would be inflated), and the intercept would be at a weighted average of 10 and 16, where the weights are proportional to the group-sizes. Note that here the omitted variable is small (its mean is 0.5) and its effect isn't especially large. If its mean was larger or the coefficient were bigger, the impact on the intercept can be correspondingly larger.
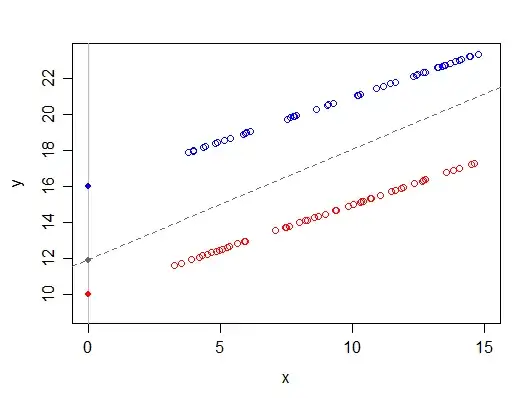
In some situations, particularly when some IV means are large and the IVs are strongly related, the effects on intercept may be really large. Taking the same relationship above (which is not at all an extreme example), by simply omitting some points, we get a dramatic effect on the intercept: