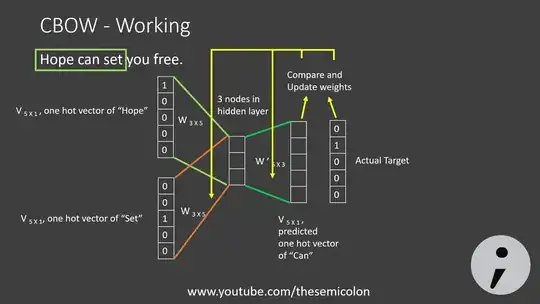
How are the words inputted into a Word2Vec model? In other words, what part of the neural network is used to derive the vector representations of the words?
As we can see from the above diagram, the words, "Hope" and "Set", are indexed as 1's in the vector, and then the $W_{3*5}$ matrix is used to derive the vector representation of the words.
What part of the neural network are the context vectors pulled from?
Word embedding vectors are fulled from the $W_{3*5}$ matrix, and context vectors are fulled from the $W'_{5*3}$ matrix.
What is the objective function which is being minimized?
The objective function is the cross entropy to compare the predicted probabilities and the actual targets.
There are two features in Word2Vec to speed things up:
Skip-gram Negative Sampling (SGNS)
It changes the Softmax over the whole vocabulary to a multilable classification(multiple binary softmax functions) function over one right target and a few negatives sampled randomly, and then instead of updating all weights only a small part weight should be updated in each backpropogation pass.
Hierarchical Softmax
Only the nodes along the path in the Huffman tree from the root to the word are considered[2].
