I have roughly 15,000 non-independent features for each of which I have a sample size of 100. For each of these feature-sample data points, I have a value of TRUE or FALSE corresponding to some status of the feature, such that for each feature, I have 100 TRUE or FALSE values.
How can I test the "trueness" of each feature and thereby determine the percentage of features with a significant TRUE value? A suitable null hypothesis may be that the feature does not have a TRUE status. My problem though is that an $\alpha$ of 0.05 corresponding to a rejection of the null hypothesis if there are >95 TRUES for a feature, seems too high. I have no reference dataset by which to make a comparison.
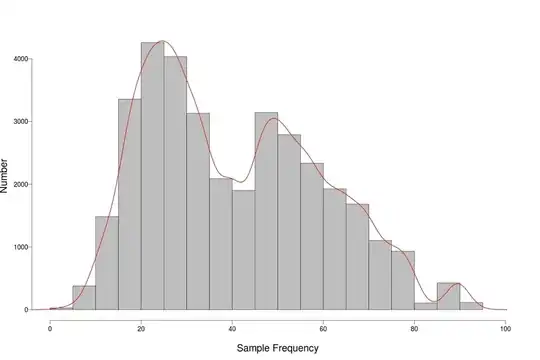
UPDATE: Re: Use of Fisher's exact test.
I am not sure what parameters to use for the 2 x 2 contingency table using Fisher's exact test or chi-squared test. What would class 1, class 2, sample 1 and sample 2 be? 'TRUE count', etc.? Here are the first few rows and columns of the data:
Sample1 Sample2 Sample3 Sample4 Sample5 Sample6 Sample7 Sample8 Sample9 Sample10
Feature1 TRUE FALSE TRUE FALSE TRUE TRUE FALSE TRUE FALSE FALSE
Feature2 TRUE FALSE TRUE FALSE TRUE TRUE FALSE TRUE FALSE FALSE
Feature3 TRUE FALSE TRUE FALSE TRUE TRUE FALSE TRUE FALSE FALSE
Feature4 TRUE FALSE TRUE FALSE TRUE TRUE FALSE TRUE FALSE FALSE
Feature5 TRUE FALSE TRUE FALSE TRUE TRUE FALSE TRUE FALSE FALSE
Feature6 TRUE FALSE TRUE FALSE TRUE TRUE FALSE TRUE FALSE FALSE
Feature7 TRUE FALSE TRUE FALSE TRUE TRUE FALSE TRUE FALSE FALSE
Feature8 FALSE FALSE TRUE FALSE TRUE TRUE FALSE TRUE FALSE FALSE
Feature9 FALSE FALSE TRUE FALSE TRUE TRUE FALSE TRUE FALSE FALSE
Feature10 FALSE FALSE TRUE FALSE TRUE TRUE FALSE TRUE FALSE FALSE
Feature11 FALSE FALSE TRUE FALSE TRUE TRUE FALSE TRUE FALSE TRUE
Feature12 FALSE FALSE TRUE FALSE TRUE TRUE TRUE TRUE FALSE TRUE
Feature13 FALSE TRUE TRUE FALSE FALSE TRUE TRUE TRUE FALSE TRUE
Feature14 FALSE TRUE TRUE FALSE FALSE TRUE TRUE TRUE FALSE TRUE
Feature15 FALSE TRUE FALSE FALSE FALSE TRUE TRUE TRUE FALSE TRUE