Check RTEFC ("Real Time Exponential Filter Clustering") or RTMAC ("Real Time Moving Average Clustering), which are efficient, simple real-time variants of K-means, suited for real time use when prototype clustering is appropriate. They cluster sequences of vectors. See https://gregstanleyandassociates.com/whitepapers/BDAC/Clustering/clustering.htm
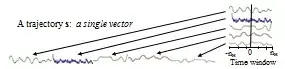
and the associated material on representing multivariate time series as one larger vector at each time step (the representation for "BDAC"), with a sliding time window. Pictorially,
These were developed to simultaneously accomplish both filtering of noise and clustering in real time to recognize and track different conditions. RTMAC limits memory growth by retaining the most recent observations close to a given cluster. RTEFC only retains the centroids from one time step to the next, which is enough for many applications. Pictorially, RTEFC looks like:
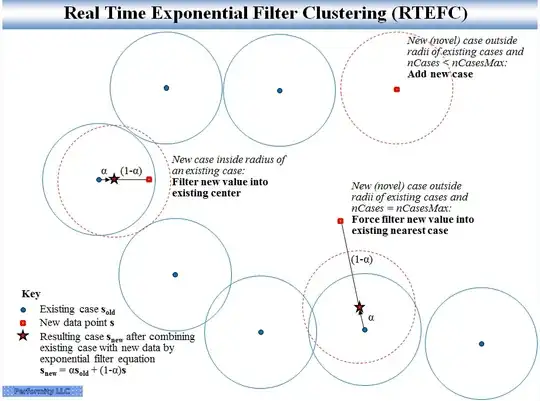
Dawg asked to compare this to HDBSCAN, in particular the approximate_predict() function. The major difference is that HDBSCAN is still assuming there is occasional retraining from original data points, an expensive operation. The HDBSCAN approximate_predict() function is used to get a quick cluster assignment for new data without retraining. In the RTEFC case, there is never any large retraining computation, because the original data points are not stored. Instead, only the cluster centers are stored. Each new data point updates only one cluster center (either creating a new one if needed and within the specified upper limit on the number of clusters, or updating one previous center). The computational cost at each step is low and predictable. So RTEFC computation would be comparable to the approximate_predict() case in finding the closest existing match, except that additionally, one cluster center is then updated with the simple filter equation (or created).
The pictures have some similarities, except the HDBSCAN picture wouldn't have the starred point indicating a recomputed cluster center for a new data point near an existing cluster, and the HDBSCAN picture would reject the new cluster case or the forced update case as outliers.
RTEFC is also optionally modified when causality is known a priori (when systems have defined inputs and outputs). The same system inputs (and initial conditions for dynamic systems) should produce the same system outputs. They don't because of noise or system changes. In that case, any distance metric used for clustering is modified to only account for closeness of the system inputs & initial conditions. So, because of the linear combination of repeated cases, noise is partly canceled, and slow adaptation to system changes occurs. The centroids are actually better representations of typical system behavior than any particular data point, because of the noise reduction.
Another difference is that all that has been developed for RTEFC is just the core algorithm. It's simple enough to implement with just a few lines of code, that is fast and with predictable maximum computation time at each step. This differs from an entire facility with lots of options. Those sorts of things are reasonable extensions. Outlier rejection, for instance, could simply require that after some time, points outside the defined distance to an existing cluster center be ignored rather than used to create new clusters or update the nearest cluster.
The goals of RTEFC are to end up with a set of representative points defining the possible behavior of an observed system, adapt to system changes over time, and optionally reduce the effect of noise in repeated cases with known causality. It's not to maintain all the original data, some of which may become obsolete as the observed system changes over time. This minimizes storage requirements as well as computing time. This set of characteristics (cluster centers as representative points are all that's needed, adaptation over time, predictable and low computation time) won't fit all applications. This could be applied to maintaining online training data sets for batch-oriented clustering, neural net function approximation models, or other scheme for analysis or model building. Example applications could include fault detection/diagnosis; process control; or other places where models can be created from the representative points or behavior just interpolated between those points. The systems being observed would be ones described mostly by a set of continuous variables, that might otherwise require modeling with algebraic equations and/or time series models (including difference equations/differential equations), as well as inequality constraints.