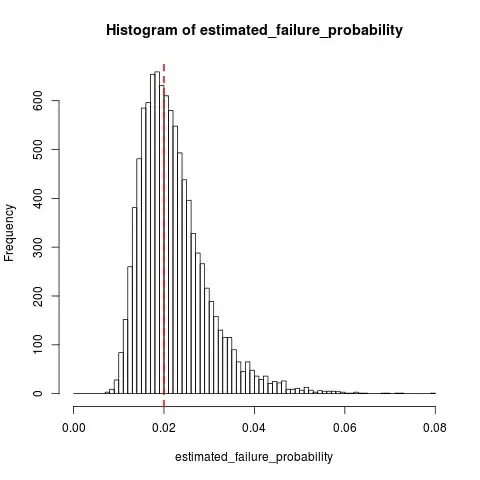
As a complement to dsaxton's answer, here are some simulations in R showing the sampling distribution of $\hat{q}$ when $k=10$ and $q_0 = 0.02$:
n_replications <- 10000
k <- 10
failure_prob <- 0.02
n_trials <- k + rnbinom(n_replications, size=k, prob=failure_prob)
all(n_trials >= k) # Sanity check, cannot have 10 failures in < 10 trials
estimated_failure_probability <- k / n_trials
histogram_breaks <- seq(0, max(estimated_failure_probability) + 0.001, 0.001)
## png("estimated_failure_probability.png")
hist(estimated_failure_probability, breaks=histogram_breaks)
abline(v=failure_prob, col="red", lty=2, lwd=2) # True failure probability in red
## dev.off()
mean(estimated_failure_probability) # Around 0.022
sd(estimated_failure_probability)
t.test(x=estimated_failure_probability, mu=failure_prob) # Interval around [0.0220, 0.0223]
It looks like $\mathbb{E}\left[ \hat{q}\right] \approx 0.022$, which is a rather small bias relative to the variability in $\hat{q}$.