This is a simple situation; let's keep it so. The key is to focus on what matters:
Obtaining a useful description of the data.
Assessing individual deviations from that description.
Assessing the possible role and influence of chance in the interpretation.
Maintaining intellectual integrity and transparency.
There are still many choices and many forms of analysis will be valid and effective. Let's illustrate one approach here that can be recommended for its adherence to these key principles.
To maintain integrity, let's split the data into halves: the observations from 1972 through 1990 and those from 1991 through 2009 (19 years in each). We will fit models to the first half and then see how well the fits work in projecting the second half. This has the added advantage of detecting significant changes that may have occurred during the second half.
To obtain a useful description, we need to (a) find a way to measure the changes and (b) fit the simplest possible model appropriate for those changes, evaluate it, and iteratively fit more complex ones to accommodate deviations from the simple models.
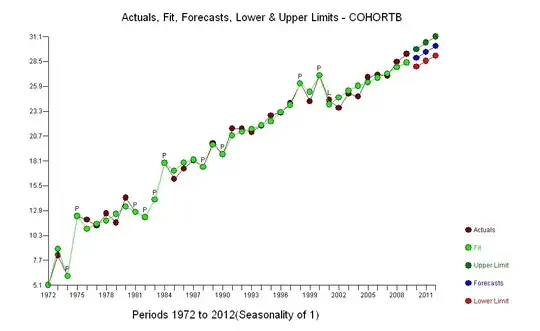
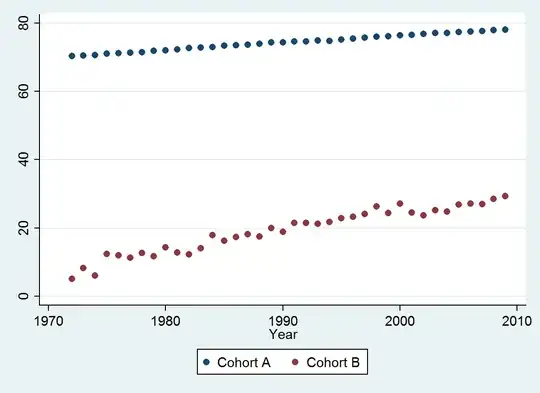
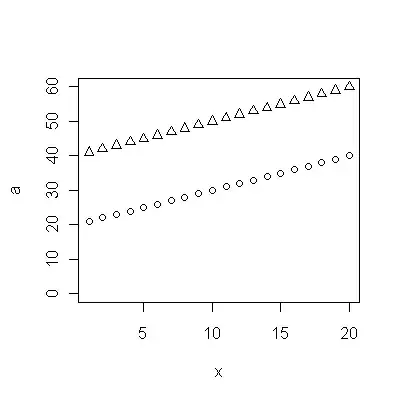
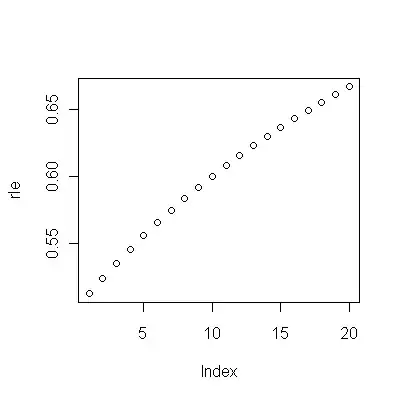
(a) You have many choices: you can look at the raw data; you can look at their annual differences; you can do the same with the logarithms (to assess relative changes); you can assess years of life lost or relative life expectancy (RLE); or many other things. After some thought, I decided to consider RLE, defined as the ratio of life expectancy in Cohort B relative to that of the (reference) Cohort A. Fortunately, as the graphs show, the life expectancy in Cohort A is increasing regularly in a stable fashion over time, so that most of the random-looking variation in the RLE will be due to changes in Cohort B.
(b) The simplest possible model to start with is a linear trend. Let's see how well it works.

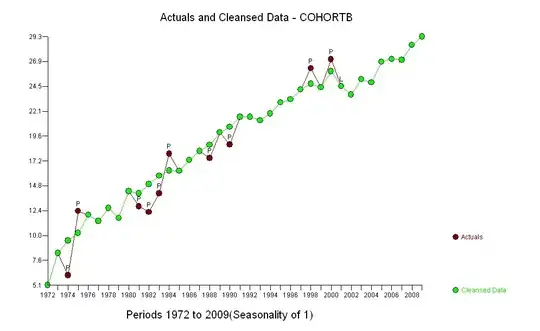
The dark blue points in this plot are the data retained for fitting; the light gold points are the subsequent data, not used for the fit. The black line is the fit, with a slope of .009/year. The dashed lines are prediction intervals for individual future values.
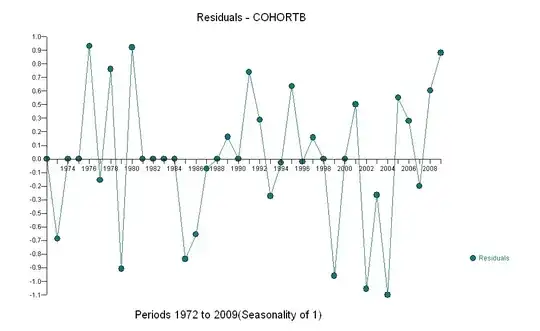
Overall, the fit looks good: examination of residuals (see below) shows no important changes in their sizes over time (during the data period 1972-1990). (There is some indication that they tended to be larger early on, when life expectancies were low. We could handle this complication by sacrificing some simplicity, but the benefits for estimating the trend are unlikely to be great.) There is just the tiniest hint of serial correlation (exhibited by some runs of positive and runs of negative residuals), but clearly this is unimportant. There are no outliers, which would be indicated by points beyond the prediction bands.
The one surprise is that in 2001 the values suddenly fell to the lower prediction band and stayed there: something rather sudden and large happened and persisted.
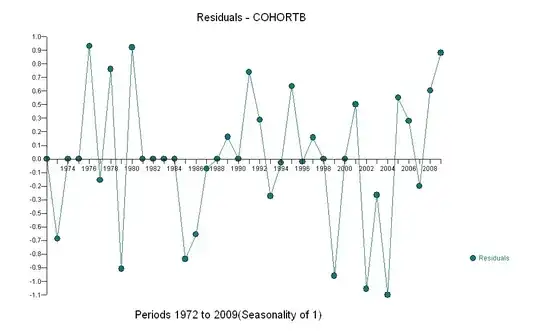
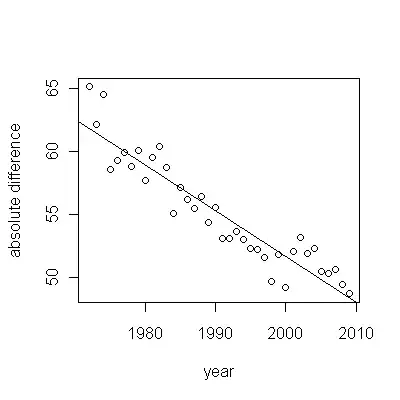
Here are the residuals, which are the deviations from the description mentioned previously.
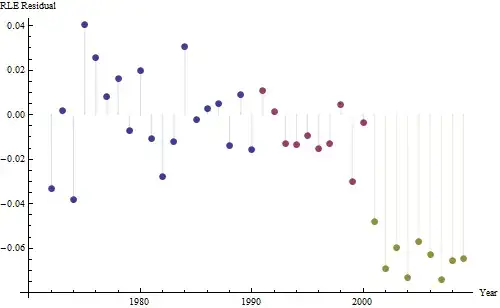
Because we want to compare the residuals to 0, vertical lines are drawn to the zero level as a visual aid. Again, the blue points show data used for the fit. The light gold ones are the residuals for data falling near the lower prediction limit, post-2000.
From this figure we can estimate that the effect of the 2000-2001 change was about -0.07. This reflects a sudden drop of 0.07 (7%) of a full lifetime within Cohort B. After that drop, the horizontal pattern of residuals shows that the previous trend continued, but at the new lower level. This part of the analysis should be considered exploratory: it was not specifically planned, but came about due to a surprising comparison between the held-out data (1991-2009) and the fit to the rest of the data.
One other thing--even using just the 19 earliest years of data, the standard error of the slope is small: it's only .0009, just one-tenth of the estimated value of .009. The corresponding t-statistic of 10, with 17 degrees of freedom, is extremely significant (the p-value is less than $10^{-7}$); that is, we can be confident the trend is not due to chance. This is one part of our assessment of the role of chance in the analysis. The other parts are the examinations of the residuals.
There appears to be no reason to fit a more complicated model to these data, at least not for the purpose of estimating whether there's a genuine trend in RLE over time: there is one. We could go further and split the data into pre-2001 values and post-2000 values in order to refine our estimates of the trends, but it wouldn't be completely honest to conduct hypothesis tests. The p-values would be artificially low, because the splitting testing were not planned in advance. But as an exploratory exercise, such estimation is fine. Learn all you can from your data! Just be careful not to deceive yourself with overfitting (which is almost sure to happen if you use more than a half dozen parameters or so or use automated fitting techniques), or data snooping: stay alert to the difference between formal confirmation and informal (but valuable) data exploration.
Let's summarize:
By selecting an appropriate measure of life expectancy (the RLE), holding out half the data, fitting a simple model, and testing that model against the remaining data, we have established with high confidence that: there was a consistent trend; it has been close to linear over a long period of time; and there was a sudden persistent drop in RLE in 2001.
Our model is strikingly parsimonious: it requires just two numbers (a slope and intercept) to describe the early data accurately. It needs a third (the date of the break, 2001) to describe an obvious but unexpected departure from this description. There are no outliers relative to this three-parameter description. The model is not going to be substantially improved by characterizing serial correlation (the focus of time-series techniques generally), attempting to describe the small individual deviations (residuals) exhibited, or introducing more complicated fits (such as adding in a quadratic time component or modeling changes in the sizes of the residuals over time).
The trend has been 0.009 RLE per year. This means that with each passing year, the life expectancy within Cohort B has had 0.009 (almost 1%) of a full expected normal lifetime added to it. Over the course of the study (37 years), that would amount to 37*0.009 = 0.34 = one-third of a full lifetime improvement. The setback in 2001 reduced that gain to about 0.28 of a full lifetime from 1972 to 2009 (even though during that period overall life expectancy increased 10%).
Although this model could be improved, it would likely need more parameters and the improvement is unlikely to be great (as the near-random behavior of the residuals attests). On whole, then, we should be content to arrive at such a compact, useful, simple description of the data for so little analytical work.
![residuals from a useful model![][1]](../../images/3812232305.webp)