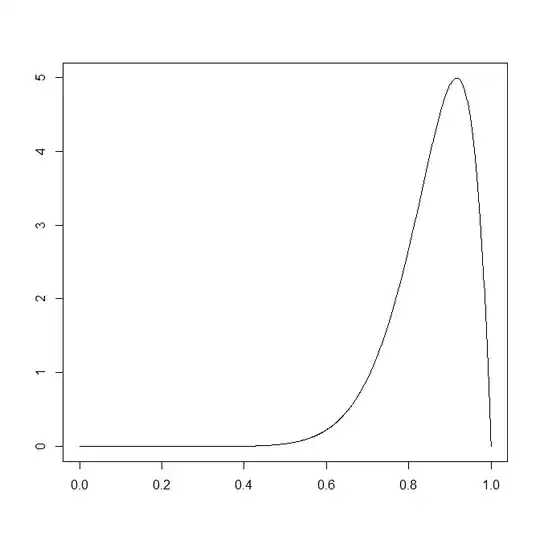
I just ran an experiment and I'm not sure how best to analyse the data. My data are distance values between objects in a metric space bounded by [0,1]. I have drawn up a probability density estimate as follows: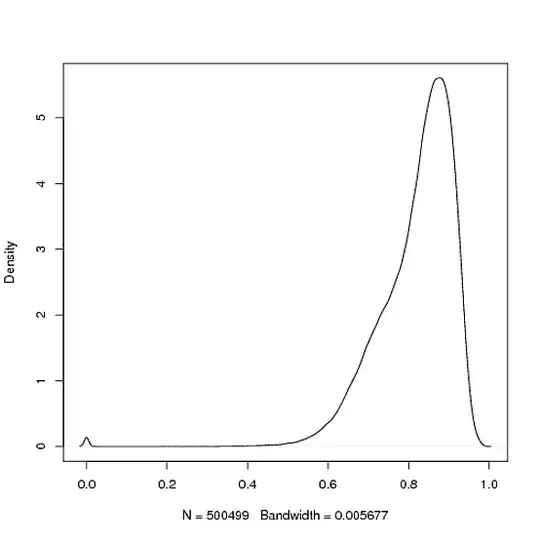
This looks to me like a kind of hybrid between an exponential and normal distribution, what tests can I run to make better sense of this?
More background:
This metric space is a finite corpus of Documents, the distance between which indicates their similarity: if the distance is 0 they are identical, if 1 they have no commonality. This sample represents all the distances between 1,000 randomly selected documents.