There are many ways to perform power calculations to determine the ideal sample size. One such way, as you mention, is to pick a threshold value of "Someone will care". This may be governed by prior knowledge, the belief that your field doesn't particular get interested until an effect is of a particular size, etc.
My suggestion is instead to look at a range of possible effect sizes. It is trivially easy, if you are performing one power calculation, to perform several to evaluate the sensitivity of your threshold. For example, will you really be alright with your study being underpowered if you set your threshold at 5% and it turns out to be 4.9%? Or 3%. Or a real effect at all?
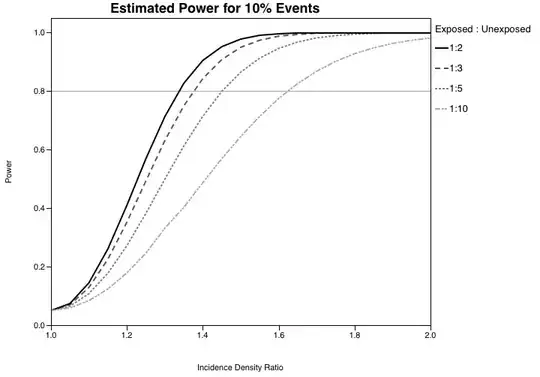
The figure below for example is asking (for a fixed sample size in this case), what the power of the study is under a range of possible Exposed:Unexposed ratios and effect sizes. It would be just as easy to compose a similar plot varying study population to more fully understand your study's power.
You also seem to be asking if you can use a small sample size to "suppress" particular results. You can design a study and acknowledge that sample size constraints will result in it being underpowered for particular effect sizes, but I wouldn't deliberately do so. A null or small effect finding is still a finding, and deliberately underpowering a study seems...flawed. Also, the optimal sample size obtained from power analysis is often somewhat optimistic - it hardly ever includes missing data, an interesting sub-group analysis, or other problems that will necessitate a bigger sample. Drawing a hard line is a bad idea.