I am doing some research using logistic regression. 10 variables influence the dependent variable. One of the aforementioned is categorical (e.g., express delivery, standard delivery, etc.). Now I want to rank those categories based on the "strength" of their effect on the dependent variable.
They are all significant (small p-value), but I think I can't just use the value of the odds for ranking purposes. I somehow need to figure out, if each category is also significantly different from the other categories. Is this correct?
I read about the possibility of centering the variable. Is this really an option? I do not want the rest of my model to be affected.
Stata output in order to support my comment to @subra's post:
Average marginal effects Number of obs = 124773
Model VCE : OIM
Expression : Pr(return), predict()
dy/dx w.r.t. : ExpDel
------------------------------------------------------------------------------
| Delta-method
| dy/dx Std. Err. z P>|z| [95% Conf. Interval]
-------------+----------------------------------------------------------------
ExpDel | .1054605 .0147972 7.36 0.000 .0798584 .1378626
------------------------------------------------------------------------------
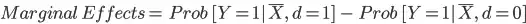
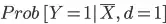 is the probability of event evaluated at mean when d=1
is the probability of event evaluated at mean when d=1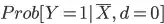 is the probability of event evaluated at mean when d=0
is the probability of event evaluated at mean when d=0