A professor in one of my graduate statistics courses once said, when briefly reviewing simple linear regression: "I would never EVER fit a line to fewer than 8-10 data points, it would make me feel...rather uncomfortable." Many of us would agree, as evidenced by "rules of thumb" suggested previously on CV here, here, and here for regression (i.e., "10 samples per covariate").
A regression line like this one ($n$ = 10) might represent this "minimum comfort level":
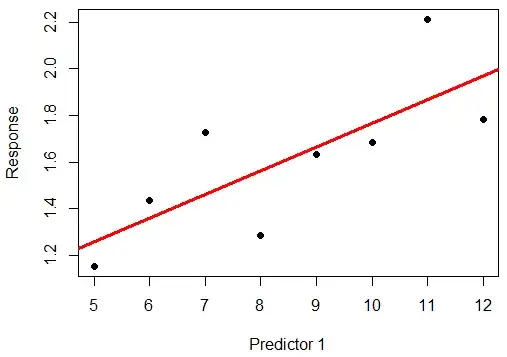
Naturally, our level of confidence in the relationship between Predictor 1 and Response would rise if we had 10 repeated samples at each x-value (for $n$ = 100):
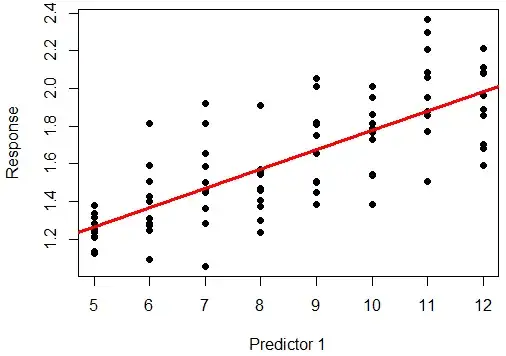
Now, suppose we have a second predictor and want to fit a plane $y$ = $\beta_0$ + $\beta_1$$x_1$ + $\beta_2$$x_2$ + $e$ or even a non-linear interaction $y$ = $\beta_0$ + $\beta_1$$x_1$ + $\beta_2$$x_2$ + $\beta_3$$x_1$*$x_2$ + $e$. Like the example above, suppose we have $n$ = 100, and these 100 samples are repeated 10 times at 10 "unique" predictor values (in this case, 10 unique $x_1$-$x_2$ combinations). Therefore, we have a relatively large sample size ($n$ = 100) for a relatively small number of predictors $n$ = 2, which, given our rule of thumb, would be generally acceptable.
(Left, linear plane; Right, non-linear surface):
My questions are:
- Would repeated samples ("stacking" at the unique $x_1$-$x_2$ combos) improve your confidence in the fit of a plane (as they did in the fitting of a line), given that these samples do not appear to give us more information about un-sampled locations on the plane? Why or why not?
- Given your response to question 1, would you "feel comfortable" fitting an interaction term $x_1$*$x_2$, as I have shown in the graph above (right)?
I look forward to discussion.