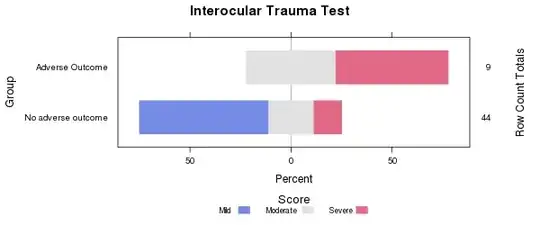
I'm doing a project about dilated kidneys, these can be arranged into mild, moderate and severe. There are 53 patients in total. I want to see if there is a trend in the severity of dilatation between those that have an 'adverse outcome' (like surgery, scarring etc) and those who do not.
Here is my data:
mild(1) mod(2) severe(3) Total
Adverse outcome ---0---------------- 4-----------------5--------------------9
No adverse outcome-28--------------10---------------- 6------------------ 44
Total----------------------28--------------14---------------11----------------- 53
Now, i realise these numbers are fairly small. I am new to statistics and initially tried a chi-square test for linear trend using software which came out as P=0.0003. However on reflection, the data values in some of the boxes are very low (and one is zero!) - do the same minimum values apply for chi-square for linear trend as with pearsons chi-square? ie 80% expected values should be above or equal to 5. Nothing online seems to mention any particular threshold for chi-squared for trend.
If i cannot use this test, please could you let me know of an alternative ASAP? thanks a lot!