I have a running process that pings multiple servers to check they are alive. If a server is taking a long period of time to respond (>10 seconds) then this system is actioned.
I plan to automate the task of determining when to take an action on a server. Possible option is to check the response time of each system and if it exceeds threshhold then do action. Drawback of this approach is that it does not take into account that the system may have been getting slower over time and just when threshhold reached the action is taken. Also it does not cater for what initial response time may have been.
I think linear regression is a better solution, as overall response times are considered instead of most recent response time. Specifically simple linear regression as using one value to predict - response time.
These are my options using linear regression in order to make decision wether or not to take action on a server :
If the slope of the line between first data point and most recent data point exceeds a particular value (at least is increasing) then take action.
Checking if the standard deviation exceeds value then take action.
If error of prediction exceeds value then take action.
action/actioned in above text is variable - alert/remove
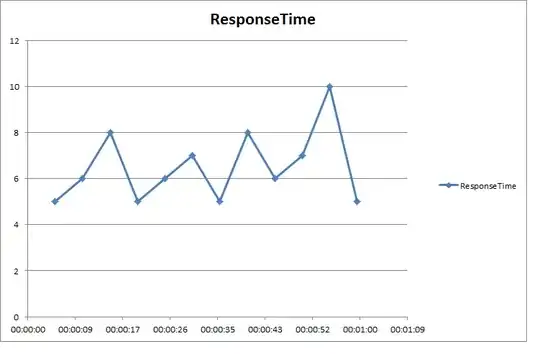
Here is sample dataset plotted (with no regression line).
Y axis - response time
X axis - time in seconds since 0
Is what ive stated in the question correct? Which option should I choose for prediction ? Is linear regression a good choice ?
