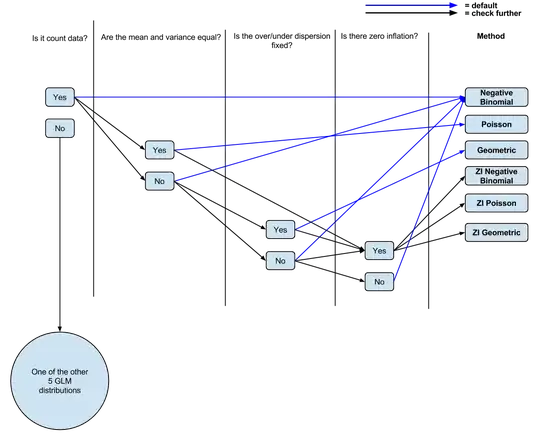
I'm trying to layout for myself when it's appropriate to use which regression type (geometric, Poisson, negative binomial) with count data, within the GLM framework (only 3 of the 8 GLM distributions are used for count data, although most of what I've read centers around the negative binomial and Poisson distributions).
When to use Poisson vs. geometric vs. negative binomial GLMs for count data?
So far I have the following logic: Is it count data? If Yes, Are the mean and variance unequal? If Yes, negative binomial regression. If no, Poisson regression. Is there zero inflation? If yes, zero inflated Poisson or zero inflated negative binomial.
Question 1 There doesn't seem to be a clear indication of which to use when. Is there something to inform that decision? From what I understand, once you switch to ZIP, the mean variance being equal assumption get's relaxed so it's pretty similar to NB again.
Question 2 Where does the geometric family fit into this or what kind of questions should I be asking of the data when deciding whether to use a geometric family in my regression?
Question 3 I see people interchanging the negative binomial and Poisson distributions all the time but not geometric, so I'm guessing there's something distinctly different about when to use it. If so, what is it?
P.S.
I've made a (probably oversimplified, from the comments) diagram (editable) of my current understanding if people wanted to comment/tweak it for discussion.