Following are 2 plots, one of lasso using glmnet package and other 2 from randomForest (variable importance) of the mtcars data set assessing variable mpg vs others. In the lasso plot, the blue and red lines indicate lambda.min and lambda.1se, respectively.
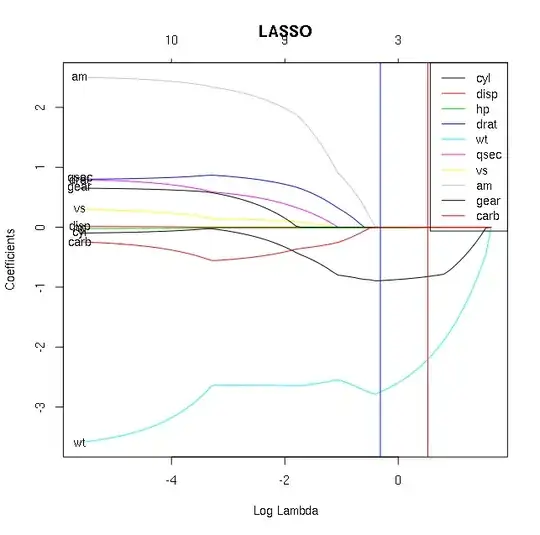
The randomForest plot gives high importance to disp and hp, which are close to 0 almost throughout the plot. Also am is of lowest importance in randomForest, though it has relatively high value in lasso plot.
What could be the reason for these discrepancies? Which one should one accept while determining important predictors of mpg in this dataset?
Edit: Both above plots was without scaling. Following are the plot after all variables (including mpg, the outcome variable) are scaled.
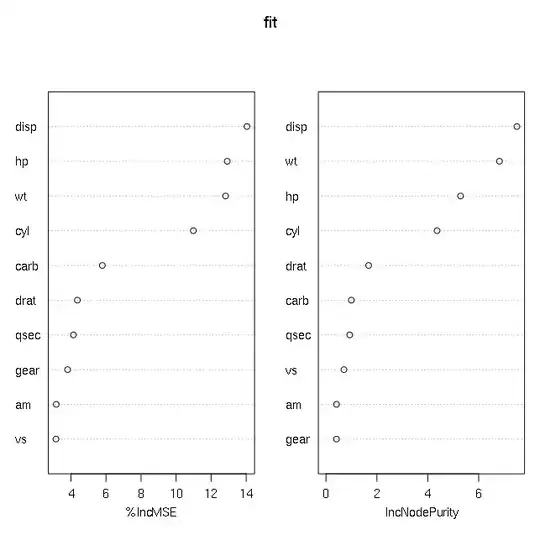
These plots are much more similar (wt, hp, cyl). But disp is still discrepant. It is highest in randomForest but very small in lasso plot.