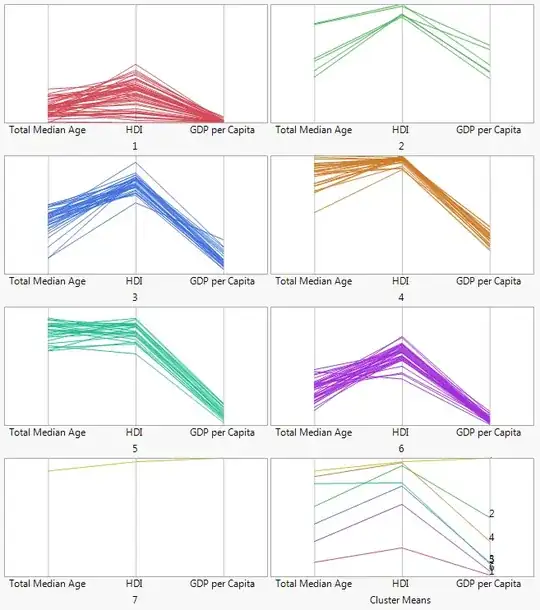
Suppose a person can be defined with 3 variables (each in the range 0-1000) which then lead to an output label Y. I have 20-40 labels.
What is a good visualization to show the flow of people to Y based on the combined effect of values in each of the three variables.
Individually for each variable, I can show then using an Alluvial Plot. Is there a way in which I can show a flow diagram on how values in all three variables lead to different Y Labels?
A many to many alluvial plot or something which does similar?
I guess alluvial plot wouldn't be the correct term as the values are not changing over time I guess. I maybe wrong.