A binary SVM classifier provides a label $y_c^{(i)}$ for each $i$-th sample provided. This is not assured to be corresponding to its true label $y^{(i)}$, since the classifier could have computed a boundary which misclassifies some samples.
Let's assume that somehow, in case of linear kernel for instance, I am able to find the distance $d$ between the $i$-th sample and the boundary, as shown in the figure.
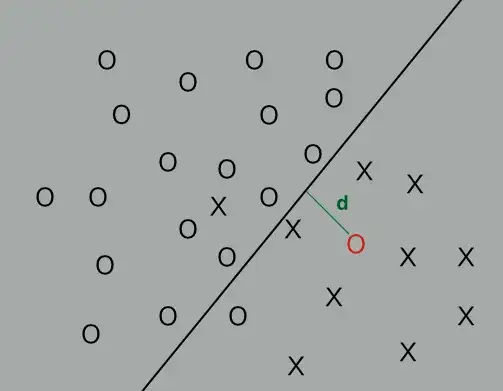
This distance somehow tells me how confident is the classifier in stating that the $i$-th sample belongs to the selected class (either positive or negative).
My problem
When a class $C$ is provided (i.e., either $C='Y'$ or $C='N'$ for binary classification), how to compute the following probability?
$Pr(y^{(i)} = C\quad |\quad y_c^{(i)})$
That is: the probability that $C$ is the true label of the $i$-th sample, given that the classifier gave the opinion $y_c^{(i)}$ on the sample.
My solution (and why it does not work)
I tried to generalize by using the true positive rate of the classifier, that is:
$Pr(y^{(i)} = C\quad |\quad y_c^{(i)}) = \frac{n_{C,y_c^{(i)}}}{\sum_{C'}n_{C',y_c^{(i)}}}$
where $n_{C,y_c^{(i)}}$ is the number of samples of class $C$ that the classifier classified as $y_c^{(i)}$. However, this measure stays as it is for every sample in the set.
What I would like to have
I would like, instead, a measure that depends on the degree of confidence of the classifier, or, somehow, on the distance $d$ computed on the boundary.
Could you please provide some suggestions?