Wikipedia reports that under the Freedman and Diaconis rule, the optimal number of bins in an histogram, $k$ should grow as
$$k\sim n^{1/3}$$
where $n$ is the sample size.
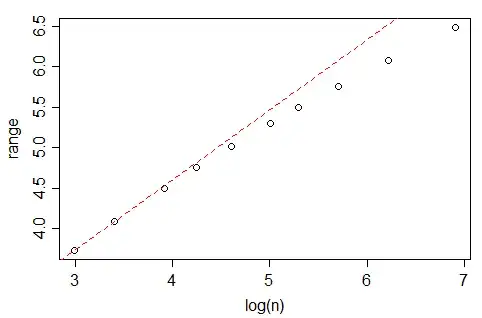
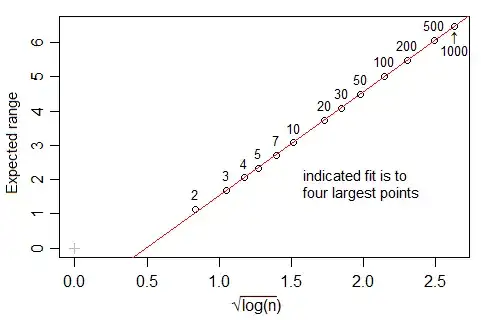
However, If you look at the nclass.FD function in R, which implements this rule, at least with Gaussian data and when $\log(n)\in(8,16)$, the number of bins seems to growth at a faster rate than $n^{1/3}$, closer to $n^{1-\sqrt{1/3}}$ (actually, the best fit suggests $m\approx n^{0.4}$). What is the rationale for this difference?
Edit: more info:
The line is the OLS one, with intercept 0.429 and slope 0.4. In each case, the data (x) was generated from a standard gaussian and fed into the nclass.FD. The plot depicts the size (length) of the vector vs the optimal number of class returned by the nclass.FD function.
Quoting from wikipedia:
A good reason why the number of bins should be proportional to $n^{1/3}$ is the following: suppose that the data are obtained as n independent realizations of a bounded probability distribution with smooth density. Then the histogram remains equally »rugged« as n tends to infinity. If $s$ is the »width« of the distribution (e. g., the standard deviation or the inter-quartile range), then the number of units in a bin (the frequency) is of order $n h/s$ and the relative standard error is of order $\sqrt{s/(n h)}$. Comparing to the next bin, the relative change of the frequency is of order $h/s$ provided that the derivative of the density is non-zero. These two are of the same order if $h$ is of order $s/n^{1/3}$, so that $k$ is of order $n^{1/3}$.
The Freedman–Diaconis rule is: $$h=2\frac{\operatorname{IQR}(x)}{n^{1/3}}$$