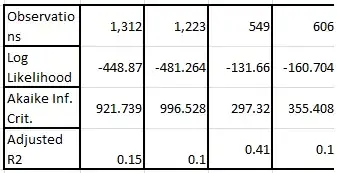
Which model is better is
1) not chosen using AIC as AIC only compares fit functions for the same data set.
2) not chosen using $R^2$ naively. For example, if two variables are supposed to be uncorrelated, then the least $R^2$ belongs to the better model.
3) $R^2$ is only proper to use (adjusted or not) if the conditions for OLS (ordinary least squares) and/or maximum likelihood are met. Rather than state what all the OLS conditions are, as there are multiple sets of rules all of which result in OLS conditions, let us state what they are not, that is, if we have very non-normal far outliers for the x-axis variable, and low $R^2$ values, the $R^2$ value is not worth the paper it is written on. In that case, we would 3a) trim the outliers or 3b) use $rs^2$ (Spearman's rank sum correlation), 3c) not use OLS or maximum likelihood, but use Theil MLR regression or an inverse problem solution, and not try to use r-values.
4) One can use 4a) Pearson Chi-Squared, 4b) t-testing for x-axis histogram categories, or if needed because of non-normality of residuals: one-sided Wilcoxon testing, and 4c) also one can test how compact each set of residuals is by comparing variances using Conover's non-parametric method (in virtually all cases) or Levene's test if normally distributed residual testing is good enough. Similarly one can use 4d) ANOVA with partial probabilities of the relevance of each fit parameter (bottoms up) AND simplify models by including all available parameters and then eliminate all unnecessary parameters by throwing in everything and eliminating parameters that are unlikely to contribute (top-down). Both top-down and bottoms-up are needed to finally decide on what model is the "best" keeping in mind that the residual structure may not be very amenable to using ANOVA and that our parameter values will most likely be biased by using OLS.
BEFORE we do believe any of the above, we should check our x-axis and y-axis variables and/or combinations of parameters to make sure we have "nice" measurements. That is, we should look at linear versus linear plots, log-log plots, exponential-exponential plots, reciprocal-reciprocal, square-root and square-root plots and all mixtures of the above and others: log-linear, linear-log, reciprocal-exponential etc., to determine which is going to produce the most normal conditions, the most symmetric residual pattern, the most homoscedastic residuals, etc., and then only test models that make sense in the "nice" context.
5) Stuff I left out or do not know about.