I have a multivariate dataset for which I have only a table including the cross-wise Euclidean distances between all points and a list giving the assignment of each point to one of several clusters. Can I use those data to calculate the within-group sum of squares within each of the clusters?
EDIT 1
Let me add an example on how I would do it, and to further explain what I want to do. Say I have the following data. I have six samples which are attributed to two clusters: S1-S3: Cluster 1 S4-S6: Cluster 2
Additionally, I have the distances between samples:
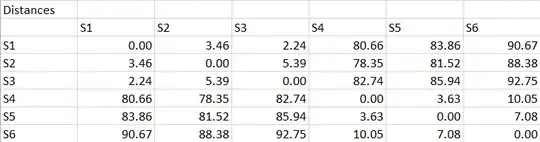
Now, if I want to calculate the sum of squares within Cluster 1, I would have the following values for the distances D: D(S1, S2) = 3.46 D(S1, S3) = 2.24 D(S2, S3) = 5.39
The mean of this would be D* = 3.70 According to the normal equation for the sum of squares TSS = sum((Di - D*)^2), as adapted from linear regression, this would lead me to TSS = sum(12.00, 2.13, 2.86), so TSS(Cluster 1) = 16.99
Equivalently: TSS(Cluster 2) = 20.66
But when I apply the same equations to the whole dataset (i.e. distances between all points) I get a TSS for the whole dendrogram of TSS(complete) = 23082.10
Finally, I would like to use all those calculations to deduce, how much of the observed variance is explained by the cluster-analysis. But if I would assume those results to be corrct (in this sense) then I would get an explained variance of only 0.16% (sum(16.99, 20.66)/23081.10).
So presumably, I make a mistake (the data were artifically produced to be explained by a dendrogram with two clusters, so the explained variance should probably be in access of 80%). Can anybody help me in this?
EDIT 2 Using the same data and the nice explanation here
I would then calculate the sum of squares per cluster as sum(Distances^2)/3. This would give me TSS(Cluster 1) = 15.33; TSS(Cluster 2) = 54.75. The total TSS of the dendrogram would then be TSS(total) = 10899.57, which would still yield an explained variance of only 0.6%.
Where am I making the mistake?