I'm comparing two groups of students by their course activity and I'm struggling a little to determine the best way to test for significant difference.
The data is non-normal, and very prevalent with zeros, so it doesn't work well with many of the more common tests.
I've tried Mood's median but the median most often ends up being zero because of the prevalence of that number. Is this OK?
If not, can anyone recommend a test which would be suitable for comparing the two rows of data above?
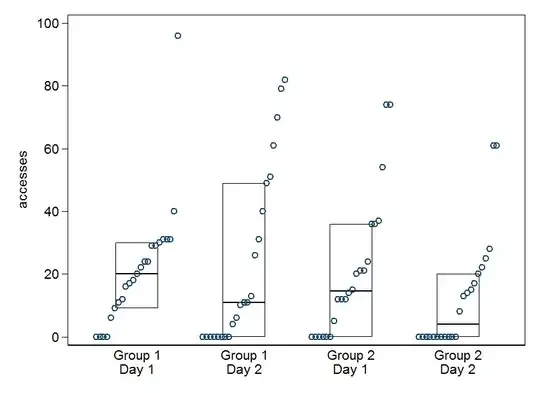
EDIT: Here is some sample data - apologies for not including copy/pastable numbers originally. I'm comparing activity on a daily basis, so Group 1 Day 1 vs Group 2 Day 1. And then comparing each day in the 5 days of the course. Each number logged within the groups records the number of times an individual student has accessed learning materials within a course. So, each number shows how 'involved' a particular student has been within a course. Each number is an individual student on that particular day. Group 1 and Group 2 have separate samples of students, but the course is the same, barring one small difference in delivery style.
Group 1 Day 1
17 29 24 40 31 96 24 31 31 30 0 0 18 16 0 0 9 12 20 29 11 6 22
Group 2 Day 1
20 24 12 74 36 54 21 74 37 21 5 12 15 0 0 0 14 0 0 0 12 36
Group 1 Day 2
82 49 11 11 79 0 31 0 61 13 0 26 51 4 6 70 40 10 0 0 0 0 0
Group 2 Day 2
28 25 0 61 14 13 0 17 0 0 61 0 22 0 0 0 0 15 8 20 0 0