I have a table like:
tabla <-data.frame(c=c(-3, -2, -1, -1, 1, 2, 3, 0, 0, 5, 4,
3, 0, 8, 9, 10, 6, 6, 7, 3, 0), e=c(0, 0, 0, 0, 0,
0, 0, 0, 0, 1, 0, 0, 0, 1, 1, 1, 0, 1, 1, 0, 1))
tabla <- tabla[order(tabla$c), ]
Let's suppose I need to predict e with c using a logistic regression:
log_pru <- glm(e ~ c, data = tabla, family = binomial(logit))
tabla$pred_res <- predict(log_pru, tabla, type = "response")
Let's suppose also that my gain is 90 when my choice is TP, and -10 when is FP function is:
mycost <- function(r, pi){
weightTP = -90 #cost for getting 1 ok -90
weightFP = 10 #cost for getting 0 wrong 10
cTP = (r==1)&(pi==1) #logical vector--- true is actual==1
#and predict ==1
cFP = (r==0)&(pi==1) #logical vector - true if actual 0
#but predict 1
return(mean(weightTP*cTP+weightFP*cFP))
}
If I'm able to identify each TP without FP, my gain would be:
maxgain <- tabla$e*90
sum(maxgain)
630
In the log model, my gain would be:
tabla$ganLog <- ifelse(tabla$pred_res>.1, tabla$e*90-10, 0)
which is 420.
I thought that introducing the cost function in the optimizing algorithm might be useful to reflect my actual problem.
So, to use "optim", I wrote the following function (which is a sigmoidal):
fn <- function(x) {
alpha <- x[1]
beta <- x[2]
J <- exp(alpha + tabla$c * beta)
prediction <- ifelse(J/(1+J) > 0.5, 1, 0)
mycost(tabla$e, prediction)
}
guess <- optim(c(0,0), fn, method='SANN')
And my result is:
alpha <- guess$par[1]
beta <- guess$par[2]
J<-exp(alpha + tabla$c * beta)
tabla$pred_guess = J/(1+ J)
plot(tabla$c, tabla$e)
lines(tabla$c, tabla$pred_guess)
mycost(tabla$e, ifelse(tabla$pred_res > 0.1, 1, 0))
tabla$ganOpt<-ifelse(tabla$pred_guess>.5, tabla$e*90-10,0)
sum(tabla$ganOpt)
Which is 460. (almost 10% greater than the obtained by the logistic with glm). If I plot both graphs:
plot(e ~ c, data=tabla)
lines(tabla$c, log_pru$fitted, type="l", col="red")
abline(0.1, 0)
abline(v=min(tabla$c[tabla$pred_res>0.1]), col="blue")
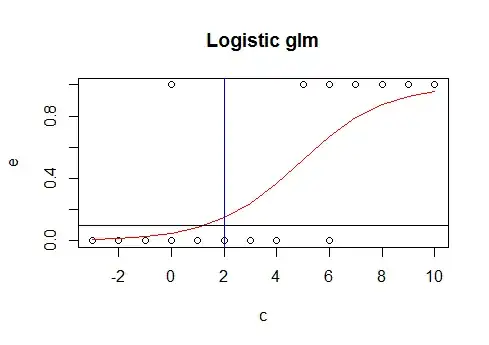
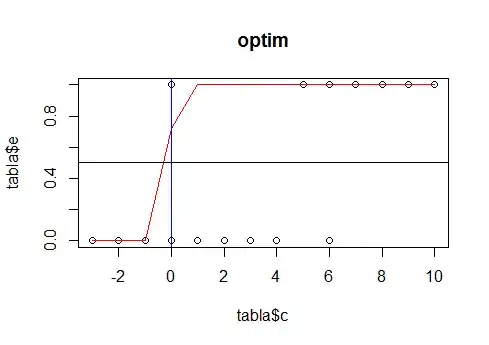
An the other model would be:
plot(tabla$c, tabla$e, main="optim")
lines(tabla$c, tabla$pred_guess, col="red")
abline(0.5, 0)
abline(v=min(tabla$c[tabla$pred_guess>0.5]), col="blue")
I know that you can introduce a cost function in cv.glm but this is only o select among models already chosen, so, my questions are:
- Would it be a good idea to introduce a cost function in the algorithm that selects the parameters?
- What does SAS do with the cost function in Miner? Does it use it to select the parameters values?
- Why glm package in R doesn't have the possibility to introduce another cost function?
- Would it be a bad idea to use "optim" in real examples? What about over-fitting? And also, do I have to program all the variables like I did in this mini example? Is there a better way?
- What about doing oversampling or downsampling to avoid this?
I would really appreciate a theoretical answer.