EDIT AFTER ACCEPTED:
It appears that your rate of failure may be decreasing over time. For example, if you regard this as a time series, it takes two differences to remove the trend, which could indicate a quadratic. And if I do try to fit it as a quadratic (and an lm and a glm):
n <- nls (y ~ a + (b * x) + (c * x^2), start=list (a=0, b=1, c=1))
curve (coef (n)[1] + (coef (n)[2] * x) + (coef (n)[3] * x^2), 0, 6000)
points (x, y)
l <- lm (y ~ x + 0)
g <- glm (y ~ x + 0, family=quasipoisson (link="identity"))
abline (0, coef (g), col="green")
abline (0, coef (l), col="red")
I get:

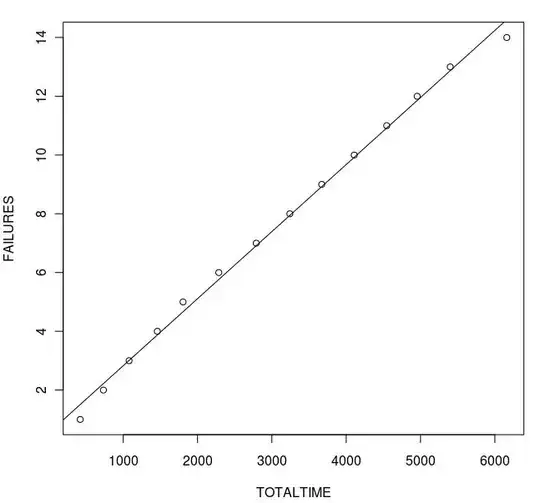
Where the quadratic (black line) looks more reasonable than the other two. (Of course "looks reasonable" does not mean "is correct", and it can't actually be a quadratic because at some point it would begin to decrease which is impossible with a cumulative sum.) In both the lm and glm, your last point is a serious outlier. (I am estimating $x$ from your graph and could be wrong. Including your actual data would be helpful.)
In light of this, it may be that the process is changing as software can: bugs being fixed, people learning to work around bugs, or the environment/process changing so that failures are less likely to be encountered. If this is the case, a linear model wouldn't be appropriate, and these "external forces" would also violate Poisson assumptions, I think.
ORIGINAL:
I believe this is basic statistics, but being self-taught I definitely have holes in my statistical knowledge. Never the less, I'll take a stab at it.
First, many models used for software bugs assume that there are a finite number of bugs that are found and each is fixed. Is your case like that? Are bugs being found and fixed in the software, or is the process in which you use the software being modified to work around bugs? If so, the number of failures per 1000 "hours" (I'll call it "hours" since I don't know your X units) will decline over time, and you get into survival time analysis and all kinds of stuff I know nothing about.
Second, if everything is in a steady state (no bugs being fixed, no process change), your data could be described as a Poisson process. Eyeballing your data, the number of errors per 1000 hours is: 2, 3, 2, 2, 2, 2, which yields an average of 2.17 errors per 1000 hours. (Leaving out the last error beyond 6000.)
Looking at the Wikipedia page for Poisson Distribution, we see that if your error rate is actually Poisson($\lambda$), then $\lambda=2.17$ (the average), and you can plot the odds of getting a given number of errors in 1000 hours as,
plot (dpois (0:6, 2.17), type="o"), and the odds of getting a number of errors or fewer in 1000 hours is plot (cumsum (dpois (1:6, 2.17)), type="o").
These odds don't change from 1000-hour period to 1000-hour period, assuming the software and process (and environment, really) are also unchanging and thus a Poisson distribution makes sense.
So, let's extrapolate, and look at your 6000-hour time period. To plot out the distribution for the expected number of errors in that time, plot (dpois (0:30, 2.17 * 6), type="o"), which nicely reflects the 13 errors you actually saw.
Not sure how to carry a Poisson analysis beyond this point.
When I look at the dpois curve, it looks to my eye like it might be close enough to normal; I'm sure there's a test for that and others here could tell us quickly. If it is close enough to normal, it would indicate that the residuals of the lm are normal, which would indicate that lm might be a reasonable thing to do. It doesn't make sense that when $x=0$ you have $y=0.545751$ (i.e. you have half a failure before you even begin). You can prevent this by using lm (var1 ~ var2 + 0), but I'm not sure if that makes sense in this case or not.
Actually, lm, like a Poisson model, assumes that your counts are not related: that the number of failures in any period of time is independent of the number of failures in previous times. You'd want to make sure that's true of your actual failures, otherwise, as IrishStat mentions, you'll get into a time-series situation which is again more complicated.