I have a data set measuring rock detection depths $Y$ based on the distance from some point of interests $X$, which are classified based on geophysical criteria. Each observation $Y$ is set after plowing the ground to determine if A) there is any chance of rock formation at all and B) what is the distance of the rock from the ground. In most cases the detection is unsuccessful and $Y$ is set to 0. Otherwise $Y$ it's set to a measure of rock depth.
There is a linear relationship between $\log(Y)$ and $\log(X)$ as shown in the plot, for $Y \ne 0$. To allow for the $Y$ log transformation I added a small constant value, 0.00001 which is an order of 10 lower than $Y$ smallest value other than 0.
:
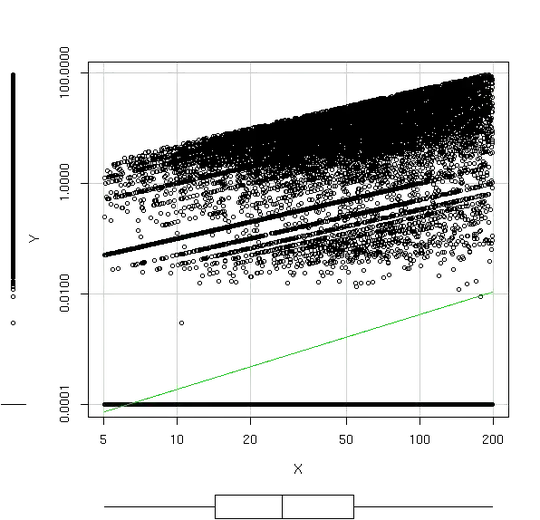
How should I model this data for prediction?
I thought about a convoluted solution using logistic regression to determine whether Y is higher than 0.0001 or not, then OLS to predict Y for each X when the result of the logistic estimator is higher than 50%. Is there a more sound approach?