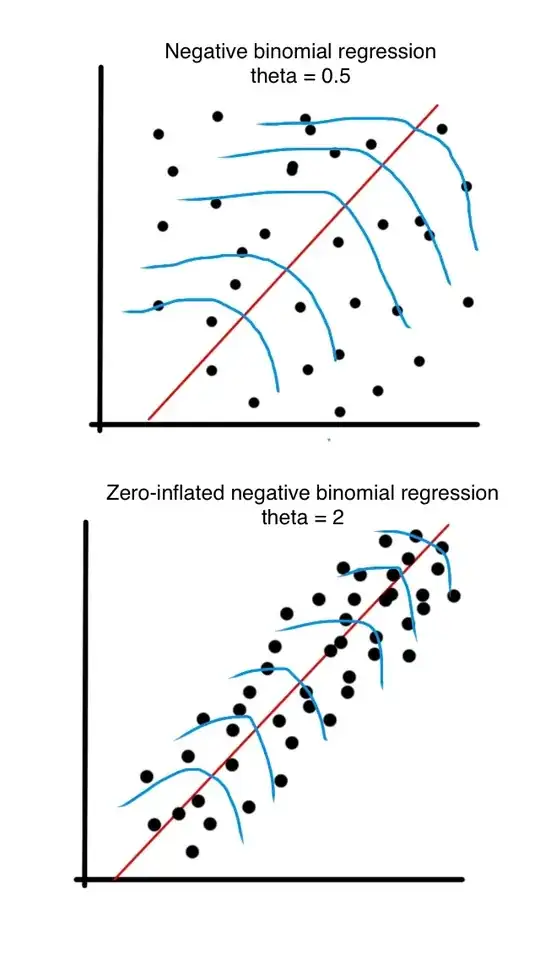
First off, a very similar question has been asked before. But the answers to this question did not explain what high/low values of theta mean. Here's my crack at trying to figure out what high/low values of theta mean. So please don't close this question!
Let's assume you've made two models: a negative binomial regression (NB) and a zero-inflated negative binomial regression (ZINB). The NB regression has a theta of 0.5 and the ZINB regression has a theta of 2. As I understand it, the higher theta in the ZINB regression indicates that more variance in the residuals has been accounted for, and therefore the negative binomial distribution that the model assumes has a more slender shape. Is this correct? Can anybody provide a more precise definition of the theta value, but without using equations?
I also quickly sketched a visualisation of my understanding. The residuals in the NB are more spread out, meaning the theta is smaller and the shape of the negative binomial distributions are more fat. The residuals in the ZINB are less spread out, meaning the theta is larger and the shape of the negative binomial distributions are more slender.