Just starting to play around with Neural Networks for fun after playing with some basic linear regression. I am an English teacher so don't have a math background and trying to read a book on this stuff is way over my head. I thought this would be a better avenue to get some basic questions answered (even though I suspect there is no easy answer). Just looking for some general guidance put in layman's terms. I am using a trial version of an Excel Add-In called NEURO XL. I apologize if these questions are too "elementary."
My first project is related to predicting a student's Verbal score on the SAT based on a number of test scores, GPA, practice exam scores, etc. as well as some qualitative data (gender: M=1, F=0; took SAT prep class: Y=1, N=0; plays varsity sports: Y=1, N=0).
In total, I have 21 variables that I would like to feed into the network, with the output being the actual score (200-800).
I have 9000 records of data spanning many years/students. Here are my questions:
1) How many records of the 9000 should I use to train the network? 1a. Should I completely randomize the selection of this training data or be more involved and make sure I include a variety of output scores and a wide range of each of the input variables?
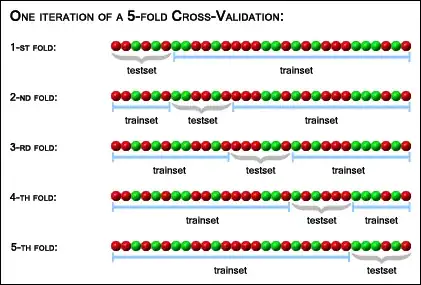
2) If I split the data into an even number, say 9$\times$1000 (or however many) and created a network for each one, then tested the results of each of these 9 on the other 8 sets to see which had the lowest MSE across the samples, would this be a valid way to "choose" the best network if I wanted to predict the scores for my incoming students (not included in this data at all)?
3) Since the scores on the tests that I am using as inputs vary in scale (some are on 1-100, and others 1-20 for example), should I normalize all of the inputs to their respective z-scores? When is this recommended vs not recommended?
4) I am predicting the actual score, but in reality, I'm NOT that concerned about the exact score but more of a range. Would my network be more accurate if I grouped the output scores into buckets and then tried to predict this number instead of the actual score?
E.g.
750-800 = 10
700-740 = 9
etc.
Is there any benefit to doing this or should I just go ahead and try to predict the exact score?
What if ALL I cared about was whether or not the score was above or below 600. Would I then just make the output 0(below 600) or 1(above 600)?
5a) I read somewhere that it's not good to use 0 and 1, but instead 0.1 and 0.9 - why is that?
5b) What about -1(below 600), 0(exactly 600), 1(above 600), would this work?
5c) Would the network always output -1, 0, 1 - or would it output fractions that I would then have to roundup or rounddown to finalize the prediction?
5d) Once I have found the "best" network from Question #3, would I then play around with the different parameters (number of epochs, number of neurons in hidden layer, momentum, learning rate, etc.) to optimize this further?
6a) What about the Activation Function? Will Log-sigmoid do the trick or should I try the other options my software has as well (threshold, hyperbolic tangent, zero-based log-sigmoid).
6b) What is the difference between log-sigmoid and zero-based log-sigmoid?