Context
Environmental data (e.g., pollutant concentrations in water, soil, air) are often lognormally distributed. Even when they are not, we tend to assume that they are (for better or worse).
Because of this, 99.5% of the time that I create boxplots, they are presented with a log-scaled concentration axis. Here's an example:
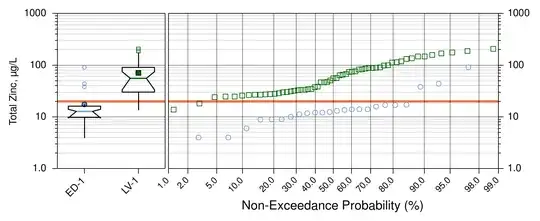
It occurs to me that computing the lower fence as $Q_1 - (1.5 \times \mathrm{IQR})$ may not be the best way when the data are presumed to be lognormal.
(Restated) Question
Given that, for me, the main value of defining the fences as with $1.5 \times \mathrm{IQR}$ is detecting potential outliers, should I define those fences and outliers in log-space, or keep everything in arithmetic space?
I'm currently leaning towards log-transforming the data, but have concerns that this may cause undue confusion or even not be an acceptable practice.
Similar questions
The accepted answer to this question: Is there a boxplot variant for Poisson distributed data? suggests simply transforming the data -- in that case by taking the square root. I'm specifically curious if the fences should be computed in log-space and then converted back to arithmetic space.