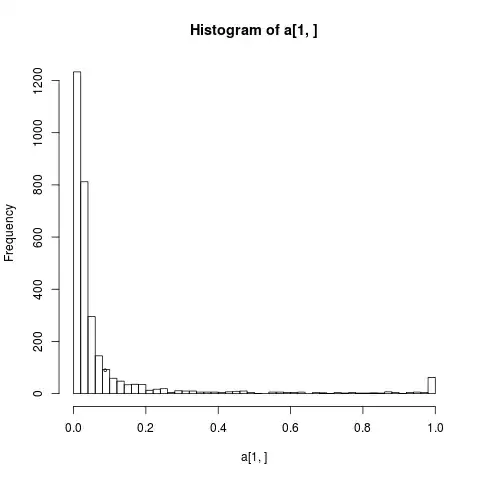
I'm trying to use central limit theorem to compute the mean of the sample, however the population where I'm sampling has value only between 0 and 1, can I use mean of the sample as mean of the population and standard error = (population's standard error / sqrt(n))?
I have done it, but the distribution does not seem a Normal, for example, I have a population with mean = 0.9895348 and SD = 0.05908021, then I'm assuming that mean of the sample should be 0.9895348 and for a sample of n = 78 the SD of the sample mean = 0.006689516.
I sampled 2000 times a random sample of n = 78, and the histogram I attached below. It does not seems a Normal, and the mean seems to be on the left where it should be, and the SD seems to be greater than 0.006689516.
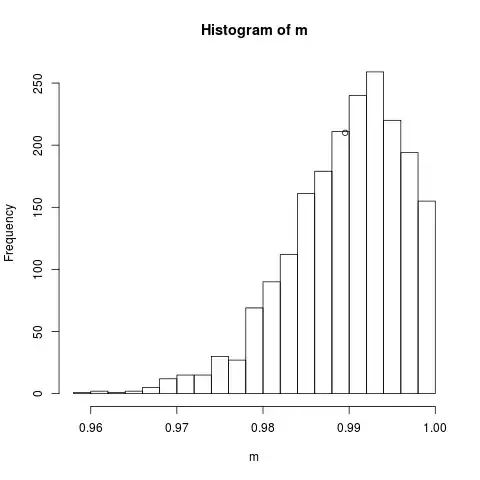
Edit: What I want is the best way to calculate the expected value of mean of a random sampling from this population. When the mean is close to 0 or 1, in my opinion, the expected value does not seem fine. When it is close to 0 the expected value seems to be greater than it should be, and when it is close to 1 it seems to be lower than it should be.
It is a synthetic dataset, where every point has a probability, below has a histogram of the data:
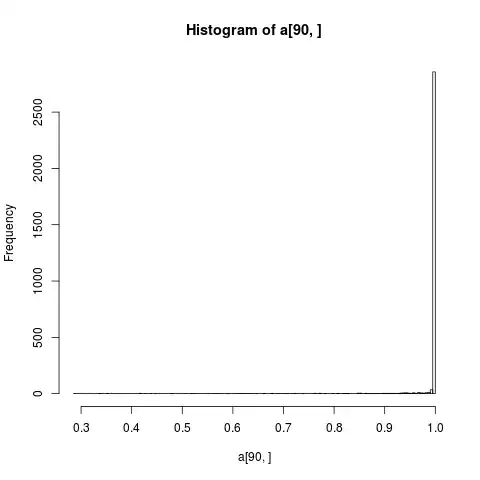
Another dataset, when the mean is close to 0, here the mean is ploted as a point, but I think the expected value should be lower