Apologies from the go as this question comes from an absolute newbie and will definitely not satisfy a lot of the detail required. Hence, your guidance in providing you the right information to allow for the adequate answering of my question may be inevitable.
A brief summary of what's nagging at my mind currently. I have received a dataset from a colleague, which contains ~5000 patients and we're trying to determine how an initial treatment affects various outcome variables. Some of these are categorical (with 3 levels), some are continuous. The categorical variable is currently the least of my concerns, because as far as I can tell, I would have to perform multivariate regression, perhaps using MANOVA, to see how this dependent variable is affected by the other independent variables.
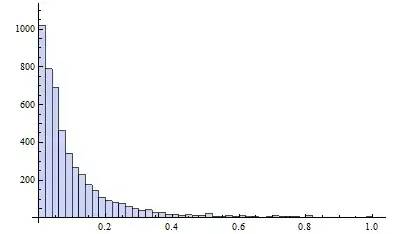
Now, what really bothers me is the distribution of the continuous data. This data consists of classic "count" data (number of times the doctor was visited following treatment) but then contains "time to heal". The "count" data would assume a Poisson distribution, but in this case var>mean ... so perhaps a quasi-Poisson would be more adequate. The distribution of that "count" data is depicted in figure 1.
Now the time to heal is what's really bugging me. Some people would argue, that this would require linear regression modelling, but what I can't get my head around, is that time to heal, cannot be zero or take on negative numbers. And if one looks at the distribution of the data, it looks a lot more Poisson than anything else (Figure 2). So would this in fact require Poisson regression? Also biologically, time to heal is probably not completely linear, but more along what we see in cell culture growth, that it has a more exponential pattern, with a linear phase in it.
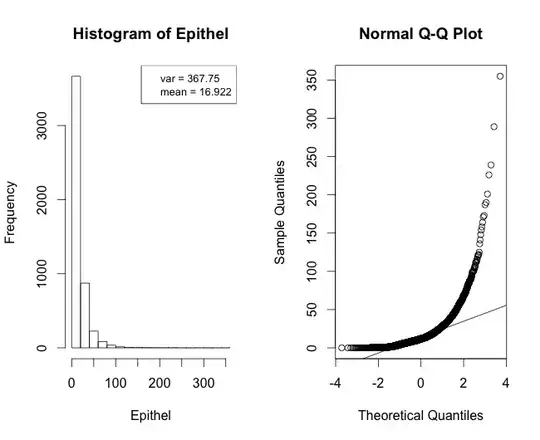
OR - and this brings me to the question in my title - because of the size of the dataset, which is fairly large, could one say that the central limit theorem holds true and I don't have to worry about the data-distribution? Clearly my plots tell me I do, no?!?
If I log-transform my data, things start to look quite ok (Figure 3)...but is a linear model adequate as the values cannot be negative or zero?

I've plotted the residuals of a linear regression model for the time to heal data in Figure 4, which shows that the tails don't really hold true to linearity. Then I plotted the residuals of the regression using a Poisson regression (Figure 5). Then the residuals of a linear regression model using log-transformation (Figure 6).
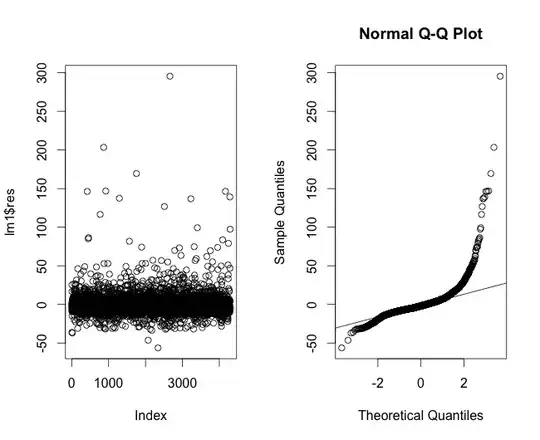
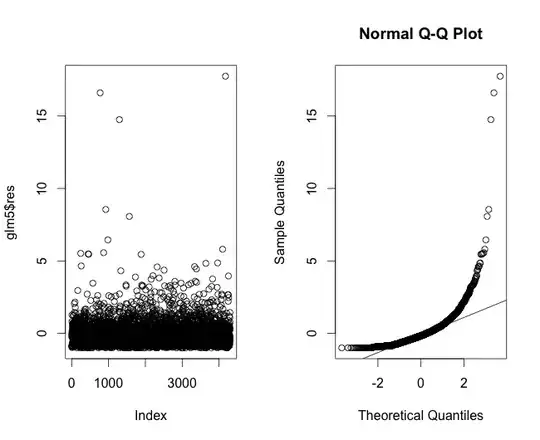
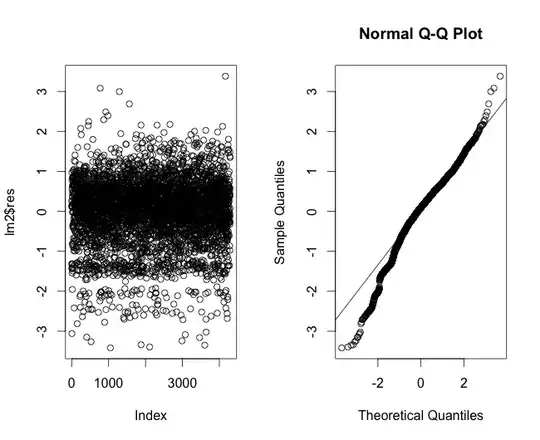
Just by looking at what you have here, what more information would you require? Am I going down a completely wrong path here? And if we assume an exponential curve for time to heal, what do I have to do to correct for this in my modelling process? And just because of the rule of numbers, could I spare myself all this thinking and simply assume that the CLT holds true?
I am very new to this, so any guidance would be more than welcome.
Hope not to have wasted anyone's time and apologize if I'm not posting crucial information here. Happy to learn, what more is required.