I am trying to put together a data-mining package for StackExchange sites and in particular, I am stuck in trying to determine the "most interesting" questions. I would like to use the question score, but remove the bias due to the number of views, but I don't know how to approach this rigorously.
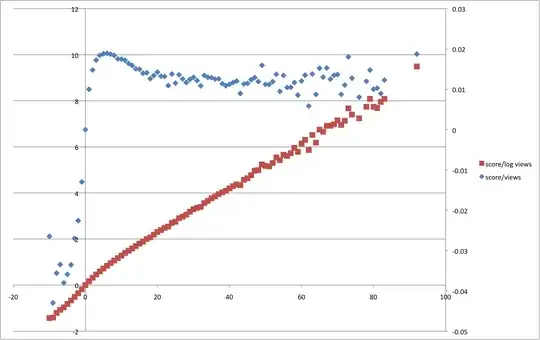
In the ideal world, I could sort the questions by calculating $\frac{v}{n}$, where $v$ is the votes total and $n$ is the number of views. After all it would measure the percentage of people that upvote the question, minus the percentage of people that downvote the question.
Unfortunately, the voting pattern is much more complicated. Votes tend to "plateau" to a certain level and this has the effect of drastically underestimating wildly popular questions. In practice, a question with 1 view and 1 upvote would certainly score and be sorted higher than any other question with 10,000 views, but less than 10,000 votes.
I am currently using $\frac{v}{\log{n}+1}$ as an empirical formula, but I would like to be precise. How can I approach this problem with mathematical rigorousness?
In order to address some of the comments, I'll try to restate the problem in a better way:
Let's say I have a question with $v_0$ votes total and $n_0$ views. I would like to be able to estimate what votes total $v_1$ is most likely when the views reach $n_1$.
In this way I could simply choose a nominal value for $n_1$ and order all the question according to the expected $v_1$ total.
I've created two queries on the SO datadump to show better the effect I am talking about:
Result:
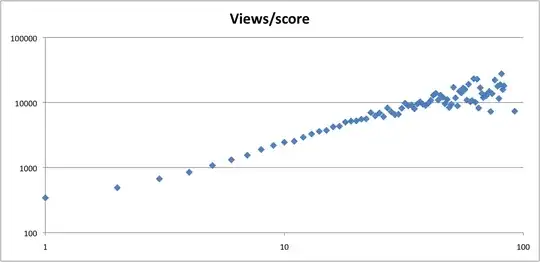
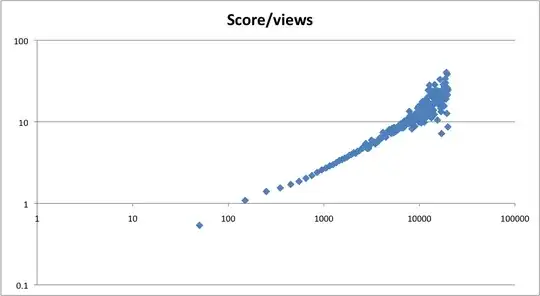
Average Score by Views (100-views buckets)
Result:
Results, not sure if straighter is better: ($\frac{v}{n}$ in blue, $\frac{v}{log{n}+1}$ in red)