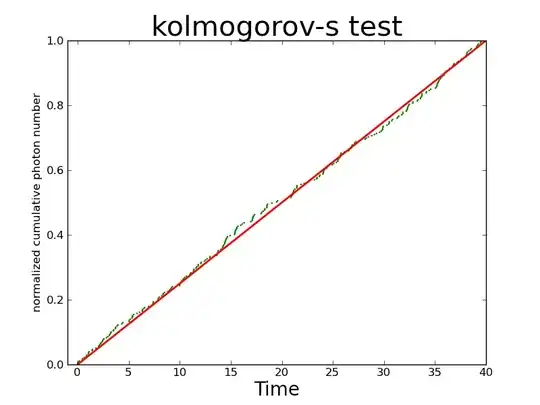
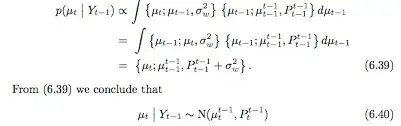A more analytic derivation for $(a)$ would be:
$$Pr(d_i=1\mid x_i) = Pr(y_i>0\mid x_i) = Pr(x_i'\beta +u_i>0\mid x_i) = 1 - Pr(x_i'\beta +u_i<0\mid x_i) = 1- Pr(u_i<-x_i'\beta\mid x_i)$$
and since the error term $u_i$ is assumed uniform $U(-0.5,0.5)$, the probability above is the value of the cumulative density function of $U(-0.5,0.5)$ at $-x_i'\beta$, so we have:
$$Pr(d_i=1\mid x_i) = 1-\frac {-x_i'\beta -(-0.5)}{0.5-(-0.5)} = 1 + x_i'\beta -0.5 = x_i'\beta +0.5$$
indeed, assuming of course that $x_i'\beta$ stays inside the support of $u_i$, i.e. that $|x_i'\beta| \leq 0.5$.
For the second requirement, the derivation is straight forward since (verifying the expression)
$$E(d_i\mid x_i) = Pr(d_i = 1\mid x_i) = P_i$$
since $d_i$ is an indicator function. Then we can write $d_i = P_i + e_i$, for which by design, $E(e_i\mid x_i)=0$. Note that this also implies that $E(e_i)=0$, by the law of iterated expectations.
For $(b)$, since $e_i = d_i-P_i$, its conditional variance is
$$\operatorname{Var}(e_i\mid x_i) = E(e_i\mid x_i)^2 = E(d_i-P_i\mid x_i)^2 = E[d_i^2\mid x_i] - 2E[d_iP_i\mid x_i] + E[P_i^2\mid x_i]$$
For indicator functions we have $d_i^2 = d_i$ so
$$\operatorname{Var}(e_i\mid x_i) = E(d_i\mid x_i) -2E[d_iP_i\mid x_i] + E[P_i^2\mid x_i]$$
$$= P_i - 2E[(P_i+e_i)P_i\mid x_i] + P_i^2 $$
(the last transformation because $P_i$ is just a function of $x_i$, so it is "measurable" (deterministic) conditional on $x_i$, and then
$$\operatorname{Var}(e_i\mid x_i) = P_i - 2P_i^2 -2 E[e_iP_i\mid x_i] + P_i^2$$
$$= P_i - P_i^2 - 2E[e_i(x_i'\beta +0.5)\mid x_i]$$
$$= P_i(1-P_i) - 2x_i'\beta E(e_i\mid x_i) - E[e_i\mid x_i] = P_i(1-P_i) -0 -0,\;\; i=1,...,n$$
I.e. what you too found is the variance of $e_i$ conditional on $x_i$ (which is what we want anyway). You wrote "$e_i$ takes the value XX with probability YY" -but these probabilities are conditional on the $x_i$ so implicitly you calculated the conditional variance.
For (c) and switching to matrix notation we have that
$$\sqrt {n}(\hat \beta_{OLS} - \beta) = (\frac 1n\mathbf P'\mathbf P)^{-1}\frac 1{\sqrt{n}} \mathbf P'\mathbf e$$
and its asymptotic variance-covariance matrix will be
$$\operatorname{AVar}(\sqrt {n}(\hat \beta_{OLS} - \beta) ) = (E[\mathbf P'\mathbf P])^{-1}E\big(\mathbf P'\mathbf e\mathbf e'\mathbf P\big)(E[\mathbf P'\mathbf P])^{-1}$$
Since the $e_i$'s are independent (because the $x_i$'s I presume are independent also, across $i$), and so they are not-autocorrelated, then
$$E\big(\mathbf P'\mathbf e\mathbf e'\mathbf P\big)$$ is consistently estimated by Whites' heteroskedasticity robust formula, for asymptotically correct standard errors.